ML products evolve quickly and this review is likely out of date. It was our best understanding of this product as of July 2021.
To avoid bias, Crosstab Data Science does not accept compensation from vendors for product reviews.
What do driver’s licenses, passports, receipts, invoices, pay stubs, and vaccination records have in common?
They are all types of forms and they contain some of society’s most valuable information. A sprawling marketplace of products has popped up to convert this information into data, a process I call form extraction. I’m interested in particular in general-purpose form extraction tools that can work with any kind of document—not just invoices, receipts, or tax forms—and off-the-shelf services that don’t require any model fine-tuning.
Amazon’s general-purpose, off-the-shelf form extraction product is Textract; launched just two years ago, it’s already the grizzled veteran of the fast-moving space. I put Textract to the test against Google Form Parser and Microsoft Form Recognizer on a challenging dataset of invoices and compared the services on ease of use, accuracy, and response time.
Textract stood out as the cheapest and easiest to use of the services I tested. The accuracy of the forms extractor was poor, but I had more success using Textract’s unstructured text extraction combined with custom logic for key-value mapping. Please see our Google Form Parser review for comparison.
Amazon Textract Highlights
| Surprise & Delight | Friction & Frustration |
|---|---|
| Unstructured text extraction is accurate and cheap. Building a heuristic key-value mapping with this output is a nice option. | PDFs must be processed asynchronously, which is slow. Async calls must pull files from an S3 bucket, they cannot be uploaded directly to Textract. |
| Pure Python response format (for the Python client) makes the output relatively straightforward to explore and learn. | Structured form output was not accurate in my testing. |
What is form extraction?
Suppose we want to use the information in our customers’ pay stubs, maybe to help them qualify for loans. A pay stub is a form; it is a stylized mapping of fields—let’s call them keys—to values. Take this example from the Gusto blog:
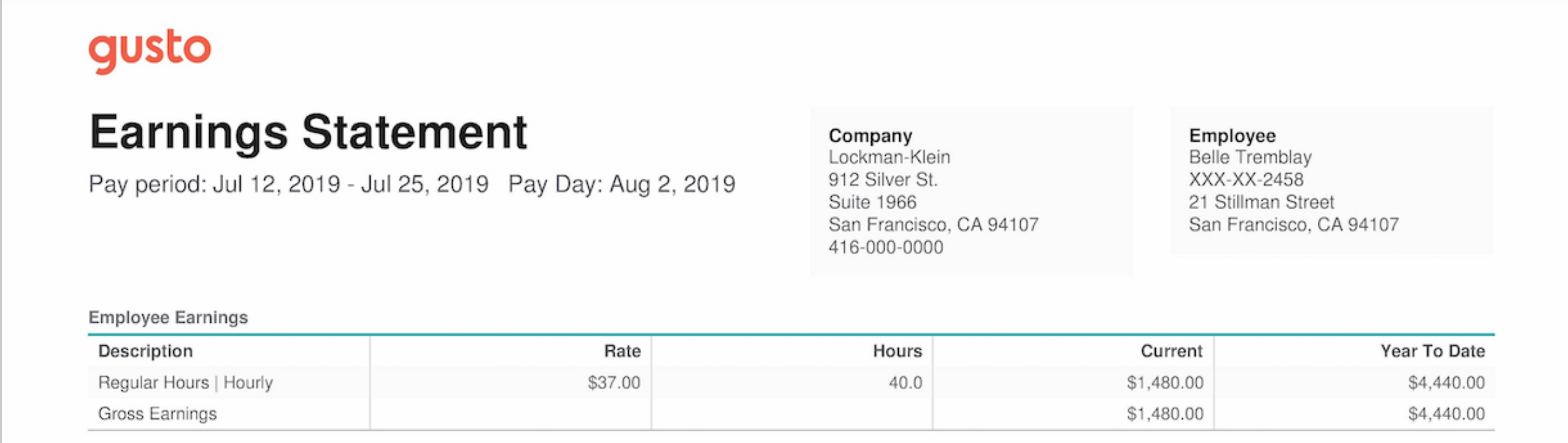
Our brains process this easily but the information is not accessible to a computer. We need the information in a data format more like this:
{
"Pay period": "Jul 12, 2019 - Jul 25, 2019",
"Pay Day": "Aug 2, 2019",
"Company": "Lockman-Klein",
"Employee": "Belle Tremblay",
"Gross Earnings": "$1,480.00"
}It’s helpful to step back and contrast this with two other information extraction tasks: optical character recognition (OCR) and template-filling. OCR tools extract raw text from images of documents; it is well-established technology but only the first step in capturing the meaning of a form.
Template-filling, on the other hand, is the holy grail; it seeks to not only extract information but slot it correctly into a predetermined schema. So far, template filling is only possible for some common and standardized types of forms like invoices, receipts, tax documents, and ID cards.1
Key-value mapping is in the middle. It’s easier than template-filling, but still hard. The Gusto demo shows why:
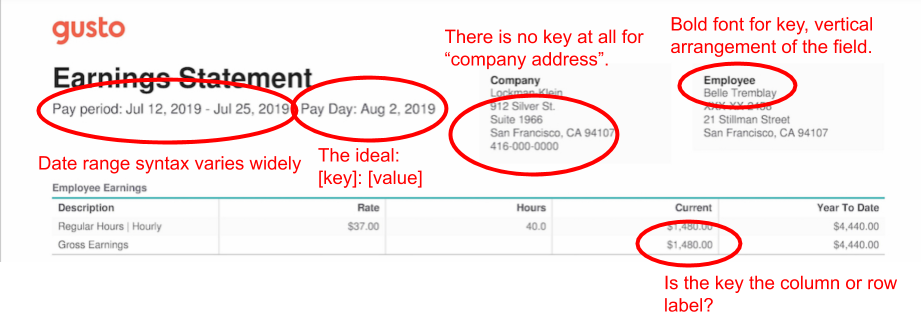
Some values have no keys. Others have two keys because they’re in tables, where the row and column labels together define the field, even though they’re far apart on the page.
The association between key and value depends on a subjective reading of page layout, punctuation, and style. Some keys and values are arranged vertically, others horizontally. Some keys are delineated by colons, others bold font.
Manually specifying field locations and formats is a non-starter because form layouts and styles vary across processors and across time. It’s not just pay stubs; US driver’s licenses, as another example, vary across states and time. Medical record formats differ between providers, facilities, and database systems.
Amazon Textract, on paper
Ecosystem
Textract is part of Amazon Web Services (AWS), the clear leader among big cloud providers. In short, if you’re already on AWS exclusively, it’s likely going to be hard to break that vendor lock-in.
Features and limitations
Textract’s API works as advertised. Its constraints should suffice for most tasks but are more restrictive than other services I tested. Some highlights from Textract’s Hard Limits and quotas pages:
Textract accepts image files in JPG or PNG format or documents in PDF format.
Image inputs must be less than 10MB.
Images can be processed synchronously or asynchronously. PDFs must be processed asynchronously.
Textract can extract data in English, Spanish, German, French, Portuguese, and Italian, but it will not tell you which language was detected.
Up to 10 synchronous transactions per second for the us-east-1 and us-west-2 regions; up to 1 synchronous transaction per second for other regions.
For async jobs, up to 10 job start calls per second and 10 fetch results calls per second in us-east-1 and us-west-2, and up to 1 call per second for each of those functions in other regions.
A max of 600 simultaneous async jobs in us-east-1 and us-west-2, 100 in other regions.
I felt quite constrained by the requirement that PDFs be processed asynchronously, especially because Google Form Parser does allow synchronous PDF processing. This constraint meant that Google processed my test PDFs in 3.3 seconds on average, while Amazon took over a minute. Simply put, Textract is not a viable solution for fast turnaround PDF jobs.
A related limitation is that documents for async calls must be uploaded to an S3 bucket first; they cannot be submitted directly to Textract. If your data is already in S3, you won’t know the difference; if not, this requirement may add substantial friction.
Textract’s rate limits and quotas feel a bit low for regions outside of us-east-1 and us-west-2, especially for synchronous operations. 1 transaction per second won’t be enough for applications with bursty traffic, like pay stub verification on alternate Fridays, or tax document processing just before deadlines.
Cost
Textract’s pricing is a bit tricky to parse. Not only do prices vary by region, but the same Textract API endpoint costs different amounts depending on what combination of tables, forms, and unstructured text the user asks for.
In the us-east-1 region, key-value pair data (but not tables) costs 5 cents per page for the first million pages per month. This is cheaper than Google’s offering (6.5 cents per page) and comparable to Microsoft’s rate for Form Recognizer.
Data policies
The Textract FAQ describes a data policy with some wrinkles. For example, Amazon claims the right to store your documents and use them to improve Textract and other ML/AI “technologies”, although you can opt-out. You can also delete input documents, but you have to explicitly request it. Other things I noticed in the data FAQ (at the time of this writing):
We do not use any personally identifiable information that may be contained in your content to target products, services or marketing to you or your end users.
What about other information in the documents? Does that imply that other information in my documents may be used for targeted ads?
… we implement appropriate and sophisticated technical and physical controls, including encryption at rest and in transit, designed to prevent unauthorized access to, or disclosure of, your content…
Only authorized employees will have access to your content that is processed by Amazon Textract.
How does this square with the encryption claim?
You always retain ownership of your content, and we will only use your content with your consent.
Again, it’s not clear how this jibes with the disclosure that Amazon may use input documents to improve any of its AI technologies.
AWS has expanded its HIPAA compliance program to include Amazon Textract as a HIPAA eligible service. If you have an executed Business Associate Agreement (BAA) with AWS, you can use Amazon Textract to extract text including protected health information (PHI) from images.
Nice.
Developer experience
Finding Textract and getting started is straightforward. With a generic AWS account, you can play with the Textract web demo to learn how the service works and test drive/sanity check the results with your documents. Code samples on Github are very helpful to get up and running. For my evaluation experiment, I relied on the PDF text example in particular.
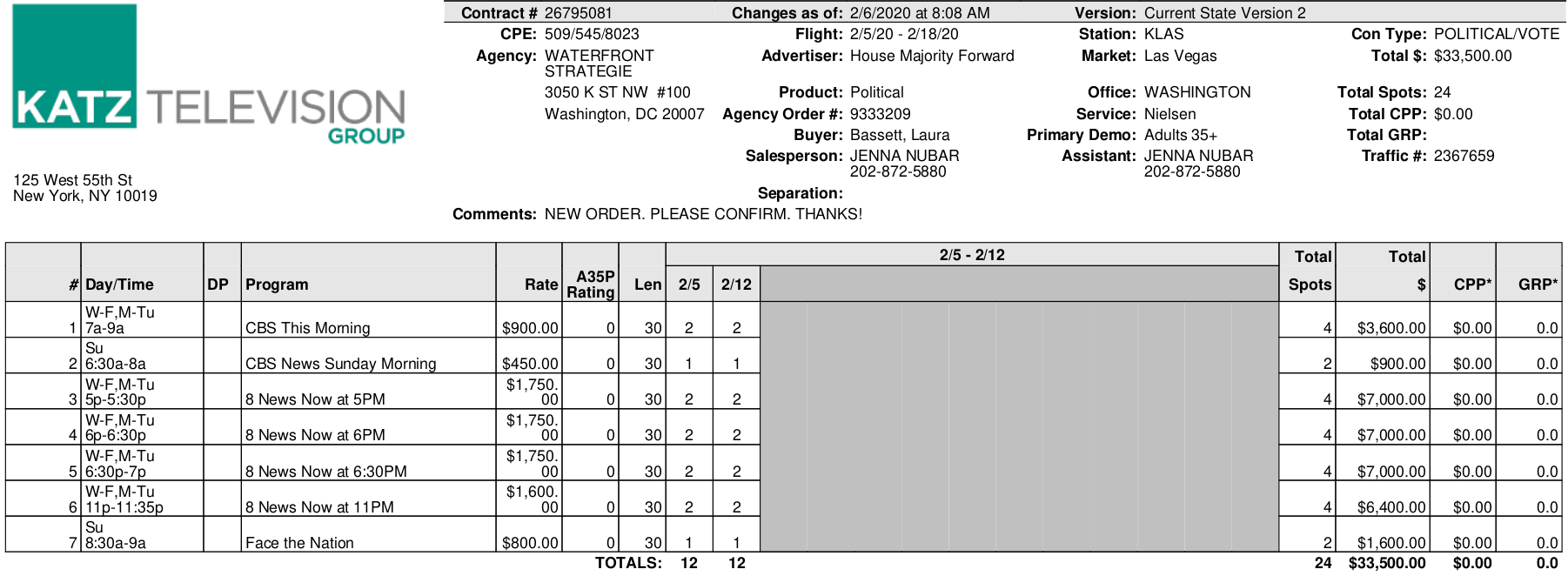
Suppose we want to parse this PDF invoice (see why in the next section):
The following Python code assumes your AWS credentials and config are already set in environment variables. Set the filename, file_path, and bucket variables before running.2
Uploading a document to S3 and starting a Textract job is short and sweet. Note the argument to the FeatureTypes parameter in the job start command (textract.start_document_analysis); the "FORMS" entry indicates I want key-value pair data, but I’ve omitted "TABLES", which would cost more. Unstructured text is included automatically with either FORMS or TABLES.
import boto3
s3 = boto3.client("s3")
textract = boto3.client("textract")
filename = "<<your filename>>"
file_path = "<<local path to your file, including the filename>>"
bucket = "<<your S3 bucket here>>"
s3.upload_file(file_path, bucket, filename)
doc_spec = {"S3Object": {"Bucket": bucket, "Name": filename}}
response = textract.start_document_analysis(
DocumentLocation=doc_spec, FeatureTypes=["FORMS"]
)
print(response["JobId"])44b9d92a6f7e473100ea07e8cdaa29967ee419f8dfedbb0221d54514ff0bfe38The requirement to use asynchronous calls for PDFs meant I had to add some complexity to my testing code, in the form of a job poller. It’s not much, but it added friction. For batch jobs, this wouldn’t be necessary—you could submit many jobs upfront then wait until you’re confident the jobs had all finished.
Note in the get_textract_results function that we need to explicitly retrieve results for all pages, using the NextToken item in the Textract response. In my example document, there is only one page.
import time
def poll_textract_job(
job_id: str,
initial_delay: float = 10,
poll_interval: float = 2.5,
max_attempts: int = 50,
) -> dict:
"""Poll for completed results for a given Textract job."""
time.sleep(initial_delay)
attempt = 0
job_status = None
while attempt < max_attempts:
response = textract.get_document_analysis(JobId=job_id)
job_status = response["JobStatus"]
if job_status != "IN_PROGRESS":
break
time.sleep(poll_interval) # Remember that `get` attempts are throttled.
attempt += 1
return job_status
def get_textract_results(job_id):
response = textract.get_document_analysis(JobId=job_id)
pages = [response]
while "NextToken" in response:
time.sleep(0.25)
response = textract.get_document_analysis(
JobId=job_id, NextToken=response["NextToken"]
)
pages.append(response)
return pages
job_status = poll_textract_job(response["JobId"])
if job_status == "SUCCEEDED":
pages = get_textract_results(response["JobId"])
print(f"Pages: {len(pages)}\nBlocks: {sum([len(p['Blocks']) for p in pages])}")Pages: 1
Blocks: 466Textract’s documentation is extensive and well-organized, which is good because working with Textract output can be confusing at first. The place to start is this diagram of Textract’s document model that illustrates the relationships between key, value, and word objects, all of which Textract calls blocks.
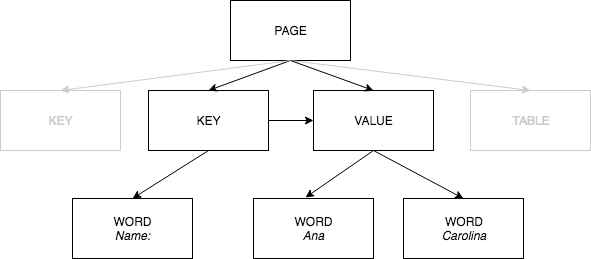
Side note: with the Python client, the Textract response is pure Python, which makes it easy to explore in a Python REPL and to serialize with pickle or json. Contrast this with Google Form Parser, which returns a custom protobuf-based object that’s harder to learn how to work with.
Ok, back to the story. Only blocks on the lowest level of the document hierarchy contain actual text; higher-level abstractions like key-value pairs contain references to their child elements. For example, the block for the key in a key-value pair looks like this:
{
'BlockType': 'KEY_VALUE_SET',
'Confidence': 56.0,
'Id': '544f3a22-a9ad-4cf1-8ec0-8c0ef9f049d0',
'Relationships': [
{'Type': 'VALUE', 'Ids': ['5235c321-3c66-4f02-889f-d2bd4db15a3f']},
{'Type': 'CHILD', 'Ids': ['9c384c5c-8a27-4d22-acc4-9cbcaebd2e5a']}
],
'EntityTypes': ['KEY'],
'Page': 3
}To get the text for this key, you have to look up the element whose ID is listed in the CHILD relationship. To get the text for the value, you first have to look up the element whose ID is listed in the VALUE element, and then look up its child. It’s a lot of boilerplate.
Here are the helper functions I wrote to pull the relevant bits out of the Textract output into a Pandas DataFrame. I don’t think it’s worth explaining line-by-line, but you are welcome to copy and use this code.
import pandas as pd
def filter_key_blocks(blocks: dict) -> list:
"""Identify blocks that are keys in extracted key-value pairs."""
return [
k
for k, v in blocks.items()
if v["BlockType"] == "KEY_VALUE_SET" and "KEY" in v["EntityTypes"]
]
def identify_block_children(block: dict) -> list:
"""Extract the blocks IDs of the given block's children.
Presumably, order matters here, and the order needs to be maintained through text
concatenation to get the full key text.
"""
child_ids = []
if "Relationships" in block.keys():
child_ids = [
ix
for link in block["Relationships"]
if link["Type"] == "CHILD"
for ix in link["Ids"]
]
return child_ids
def concat_block_texts(blocks: list) -> str:
"""Combine child block texts to get the text for an abstract block."""
return " ".join([b["Text"] for b in blocks])
def identify_value_block(block: dict) -> str:
"""Given a key block, find the ID of the corresponding value block."""
return [x for x in block["Relationships"] if x["Type"] == "VALUE"][0]["Ids"][0]
def build_pairs_dataframe(blocks: dict):
"""Convert raw Textract output into a DataFrame of key-value pairs."""
results = []
key_ids = filter_key_blocks(blocks)
for k in key_ids:
child_ids = identify_block_children(blocks[k])
child_blocks = [blocks[c] for c in child_ids]
key_text = concat_block_texts(child_blocks)
v = identify_value_block(blocks[k])
child_ids = identify_block_children(blocks[v])
child_blocks = [blocks[c] for c in child_ids]
value_text = concat_block_texts(child_blocks)
result = {
"key_id": k,
"key_text": key_text,
"key_confidence": blocks[k]["Confidence"],
"value_id": v,
"value_text": value_text,
"value_confidence": blocks[v]["Confidence"],
}
results.append(result)
return pd.DataFrame(results)
## Run it!
blocks = {block["Id"]: block for page in pages for block in page["Blocks"]}
df_pairs = build_pairs_dataframe(blocks=blocks)
df_pairs[["key_text", "key_confidence", "value_text", "value_confidence"]].head() key_text key_confidence value_text value_confidence
0 Product: 98.5 Political 98.5
1 Agency Order #: 98.5 9333209 98.5
2 Changes as of: 97.5 2/6/2020 at 8:08 AM 97.5
3 Traffic #: 97.0 2367659 97.0
4 Total CPP: 96.5 $0.00 96.5Now we have a DataFrame with the text for each key-value pair discovered by Textract, along with the IDs (omitted here) and confidence scores of the respective blocks.
Test methodology
Choosing the candidates
I first narrowed the set of potential products to those that:
- Have either a free trial or a pay-as-you-go pricing model, to avoid the enterprise sales process
- Claim to be machine learning/AI-based, vs. human-processing.
- Don’t require form fields and locations to be specified manually in advance.
- Have a self-service API.
Of the tools that met these criteria, Amazon Textract, Google Form Parser, and Microsoft Form Recognizer seemed to best fit the specifics of my test scenario.
The challenge
Suppose we want to build a service to verify and track ad campaign spending. When a customer receives an invoice from a broadcaster they upload it to our hypothetical service and we respond with a verification that the invoice is legit and matches a budgeted outlay (or not). For this challenge, we want to extract the invoice number, advertiser, start date of the invoice, and the gross amount billed.
To illustrate, the correct answers for the example invoice in the previous section are:

{
"Contract #": "26795081",
"Advertiser:": "House Majority Forward",
"Flight:": "2/5/20 - 2/18/20",
"Total $": "$33,500.00"
}To do this at scale, we need a form extraction service with some specific features:
- Key-value mapping, not just OCR for unstructured text
- Accepts PDFs
- Responds quickly, preferably synchronously.
- Handles forms with different flavors. Each broadcast network uses its own form, with a different layout and style.
We don’t need the service to handle handwritten forms, languages other than English, or images of documents. Let’s assume we don’t have a machine learning team on standby to train a custom model.
The data
The documents in my test set are TV advertisement invoices for 2020 US political campaigns. The documents were originally made available by the FCC, but I downloaded them from the Weights & Biases Project DeepForm competition. Specifically, I randomly selected 51 documents from the 1,000 listed in Project DeepForm’s 2020 manifest and downloaded the documents directly from the Project DeepForm Amazon S3 bucket fcc-updated-sample-2020.
I created my own ground-truth annotations for the 51 selected invoices because Project DeepForm’s annotations are meant for the more challenging task of template-filling.3
Evaluation criteria
I measured correctness with recall. For each test document, I count how many of the 4 ground-truth key-value pairs each service found, ignoring any other output from the API. The final score for each service is the average recall over all test documents.
I use the Jaro-Winkler string similarity function to compare extracted and ground-truth text and decide if they match.
Form Parser attaches a confidence score to each extracted snippet. I ignore this; if the correct answer is anywhere in the response, I count it as a successful hit.
The results table (below) includes a row for custom key-value mapping. For each service, I requested unstructured text in addition to the key-value pairs, then created my own key-value pairs by associating each pair of successive text blocks. For example, if the unstructured output was
["Pay Day:", "Aug 2, 2019", "912 Silver St.", "Suite 1966"]then this heuristic approach would return:
{
"Pay Day:": "Aug 2, 2019",
"Aug 2, 2019": "912 Silver St.",
"912 Silver St.": "Suite 1966"
}Most of these pairs are nonsense, but because I evaluated with recall, this naïve method turned out to be a reasonable baseline. In fact, for Textract the results were better than the explicit key-value pair extractor.
Results
Textract was in the middle of the pack in terms of accuracy, although none of the services did very well. In my test, Textract found only 2.4/4 key-value pairs correctly on average. This doesn’t seem good enough to build a product on, although I should stress that my test documents are relatively complex. Simpler documents would likely yield better results with all three of the services.
Interestingly, Textract’s unstructured text extraction was excellent, correctly finding 3.9/4 keys and (separately) 3.9/4 values, on average. My naïve, heuristic key-value mapper then correctly associated 2.9 out of 4 key-value pairs correctly, tied for the best recall out of all the methods I tried.
Because my test documents were PDFs, I was forced to use asynchronous Textract calls. I expected this to be slower than synchronous processing, but I was still surprised to see the job poller time out at 3 minutes in many cases. On average, Textract jobs took about 65 seconds to process, which is an underestimate because of the timed-out jobs. If you want to build a real-time, customer-facing product with PDF inputs, Textract is not the tool for you.
| Measure | Amazon Tetxtract | Google Form Parser | Microsoft Form Recognizer |
|---|---|---|---|
| Mean recall (out of 4) | 2.4 | 2.8 | 2.2 |
| Median recall (out of 4) | 2 | 3 | 3 |
| Mean recall, custom key-value mapping (out of 4) | 2.9 | 0.4 | 2.9 |
| Mean response time (seconds) | 65.4 | 3.3 | 25.3 |
| 90th percentile response time (seconds) | 173.1 | 4.7 | 41.1 |
Final thoughts
My final verdict on Textract is…mixed.
On the one hand, if you need real-time processing of documents in PDF format, Textract’s slow async processing takes it out of the running; use Google Form Parser instead. On the other hand, Textract’s pure Python output makes it relatively easy to learn and work with.
On one hand, Textract’s form parsing accuracy was poor in my test with real invoice documents. On the other hand, Textract’s accuracy with unstructured text was very good, and it’s not hard to build custom key-value mapping logic on top of the unstructured text.
In the end, I think it comes down to platforms. If you’re already on AWS, Textract is good enough to try. If you currently use a different cloud provider, I would try Google Form Parser before Textract.
References
- Listing image by Brett Jordan on Unsplash.
Footnotes
For invoices and receipts, in particular, see Taggun, Rossum, Google Procurement DocAI, and Microsoft Azure Form Recognizer Prebuilt Receipt model. For identity verification, try Onfido, Trulioo, or Jumio.↩︎
The code snippets in this article run with Python==3.8, boto3==1.17.103, and pandas==1.2.5. No promises with other versions.↩︎
Annotating form documents is very tricky, and I made many small decisions to keep the evaluation as simple and fair as possible. Sometimes a PDF document’s embedded text differs from the naked eye interpretation. I went with the visible text as much as possible. Sometimes a key and value that should be paired are far apart on the page, usually because they’re part of a table. I kept these in the dataset, although I chose fields that are not usually reported in tables. Dates are arranged in many different ways. When listed as a range, I have included the whole range string as the correct answer, but when separated I included only the start date.↩︎