A central tenet of machine learning is that supervised models should be evaluated based on their predictive accuracy. How to do this remains a frequent topic of discussion for practicing data scientists, however.1 What I didn’t realize until recently is that estimating predictive performance is still an active area of research as well.
My realization came via a new paper by Bates, Hastie, and Tibshirani called Cross-validation: what does it estimate and how well does it do it?. Tibshirani—eminence that he is—seems especially excited about this one, tweeting
We do two things (a) we establish, for the first time, what exactly CV is estimating and (b) we show that the SEs from CV are often WAY too small, and show how to fix them. We also show similar properties to those in (a) for bootstrap, Cp, AIC and data splitting. I'm excited!— rob tibshirani (@robtibshirani) April 1, 2021
In this article, I digest the paper’s findings, put them in context, and ponder how they might translate to data science practice in the field.
TL;DR
Bates, et al. show that the naïve way to use cross-validation to construct confidence intervals for generalization error does not work; it yields intervals that do not cover the true generalization error with the intended frequency.
The paper proposes a new algorithm based on nested cross-validation to construct a confidence interval for generalization error that traps the true error more correctly.
Bates, et al. prove that for unregularized linear models, cross-validation estimates the average generalization error across many hypothetical datasets better than it does the generalization error of the dataset and trained model we have in-hand. The authors conclude that cross-validation error is not an estimator for generalization error, but I don’t think this is a particularly useful way to see the issue for practicing data scientists.
They also show that with simple data splitting, re-fitting a model to the full dataset invalidates the generalization error estimates based on the train-test split.
The paper’s proofs require many assumptions that limit their practical relevance to situations where A. we have very small datasets, and B. we have a business reason to care about a model’s generalization error and the uncertainty in our estimate of the generalization error, and C. we use an unregularized linear model.
Despite limited practical relevance, the paper is worth the read because it’s a great reminder that we need to think more carefully about our model evaluation principles and procedures, and a heads-up that more research is likely coming that will lead the industry to update our standards.
Standard operating procedure
Model evaluation is confusing; it helps to keep a concrete example in mind.2 Let’s say we work for a company that appraises large agricultural properties. We have data on 100 recent farm sales in our operating area, and we want to train a model to predict the market value of any property in the region. To keep the plots simple, we’ll use the farm’s acreage as our only feature.
The standard operating procedure is to select the best model architecture, features, and hyperparameters using data splitting or k-fold cross-validation to avoid over-fitting to the training data.3 Simple data splitting with one randomly selected, held-out test set is ideal, but it’s not feasible in this scenario, where we have only 100 data points. Holding 20% of the data out of model training would be too damaging to model quality and wouldn’t provide a test set large enough to be reliable. K-fold cross-validation (CV) gets around these problems.
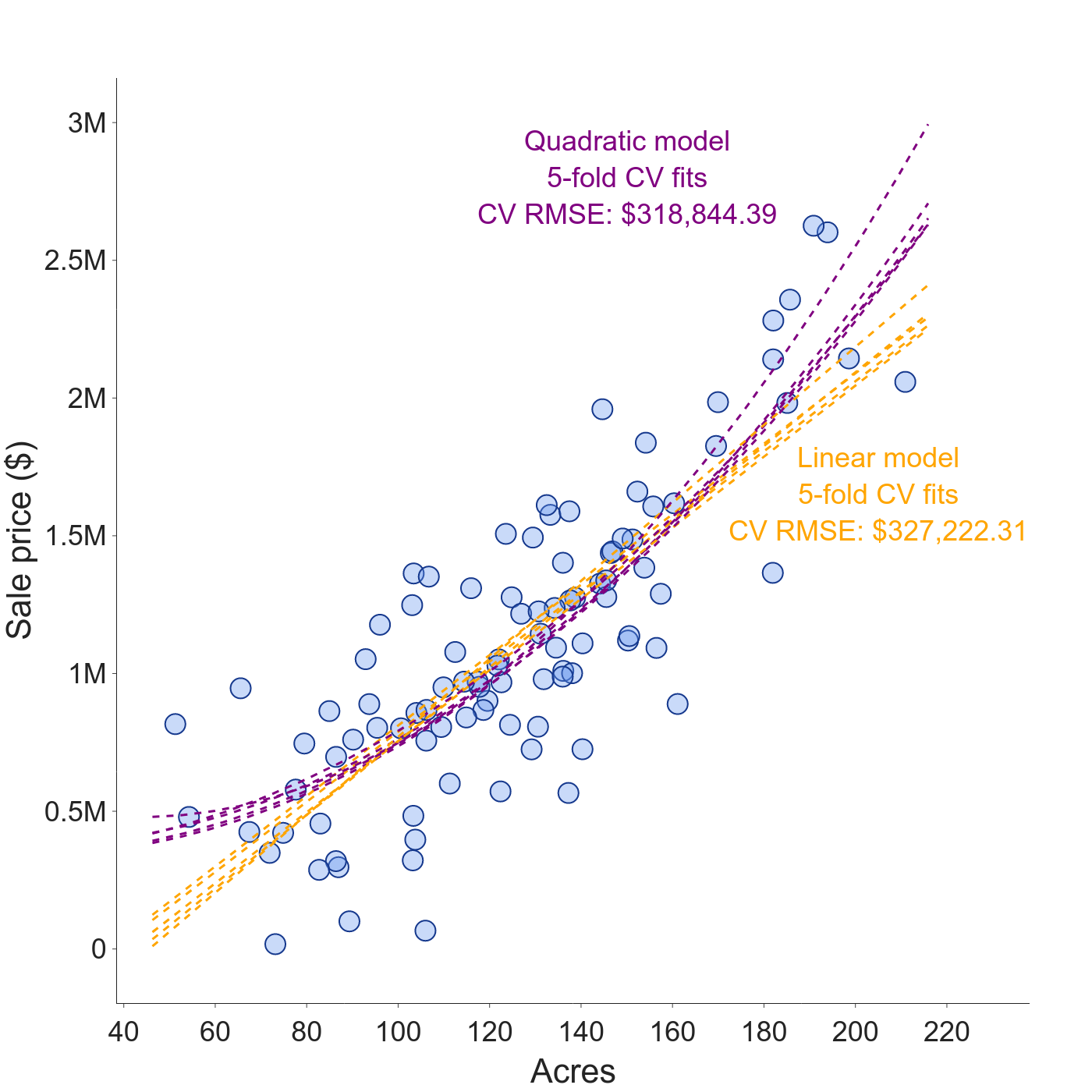
For our running example, we set \(k=5\) and use the squared error loss function. The quadratic model has a lower CV error than the linear model, so we choose that model form to re-fit to the full dataset then deploy. Nice and tidy, let’s ship it.
That’s pretty much where most instructional texts and most practitioners (including myself, historically) leave things. Not so fast.
Background and context
The standard operating procedure for model evaluation misses several important things.
What is generalization error?
When we evaluate a model’s prediction accuracy with CV or simple data splitting, we are estimating the generalization error of the model, also known as out-of-sample error, expected prediction error, test error, prediction risk, and population risk.4 Generalization error is the model’s average prediction error on new data points from the same process that generated our original dataset, where the error is measured with a loss function. Think of it as asking how well does the model generalize to previously unseen data points?
Generalization error is an unknown quantity in real-world problems, so it’s useful to ask how well we can estimate it with methods like cross-validation and data splitting.
Why do we care about generalization error?
Generalization error is the best description of a predictive model’s accuracy in deployment. As Hastie and Tibshirani (and Friedman) point out in their 2009 textbook Elements of Statistical Learning (ESL), we use estimates of generalization error in two different ways:
Model selection: choose model architecture, hyperparameters, features, and early stopping to maximize predictive performance. This is the easier of the two tasks because we only need to know that one model is better than another, but not exactly how accurate each model is.
Model assessment: estimate the generalization error of a model, as accurately as possible.
The Bates, et al. paper is about model assessment, not model selection. Frustratingly, the sources that emphasize the importance of model assessment all seem to leave the practical rationale as an exercise for the reader.
The Bates, et al. paper itself opens with
When deploying a predictive model, it is important to understand its prediction accuracy on future test points, so both good point estimates and accurate confidence intervals for prediction error are essential.
ESL (section 7.1) says
Assessment of [generalization] performance is extremely important in practice, since it…gives us a measure of the quality of the ultimately chosen model.
But so what? Why is it important to know the prediction accuracy of the final model? Under what circumstances? What if we deploy our models in staged roll-outs or A/B tests where we can directly measure generalization error in production? Don’t most of the justifications boil down to model selection in the end?
My sense is that model assessment is all about business impact (domain impact more generally, be it clinical, scientific, public policy, or something else).5 I can imagine lots of applications—forecasting customer complaints and quantifying missed churn prevention opportunities come to mind—but the most direct might be finance. Imagine a bank considering our model for underwriting mortgages; on average, they expect to make money using our model, but they’re concerned that a very large overestimate of a property’s value could bankrupt them.
There are two ways our meeting with the bank could go. On one hand, they may have already committed to using our model, in which case they need the best possible point estimate of the model’s generalization error so they can adjust their capital reserves accordingly.
Confidence intervals for generalization error
On the other hand, the hypothetical bank could instead say they can tolerate average model prediction error up to $350,000, and ask us to prove that we can meet that requirement. This task is best answered with a confidence interval for the model’s generalization error.
According to Bates, et al., the naïve way to do this is to treat generalization error like any other approximately Gaussian statistic. Let’s say we have \(n\) observations. If \(e_i\) is the test error of the \(i\)’th data point computed when that point is held out of model training, and $ {e} $ is the CV estimate of generalization error, then the estimated standard error of generalization error is
\[ \widehat{SE} = \frac{1}{\sqrt{n}}\sqrt{\frac{1}{n-1}\sum_{i=1}^{n} (e_i - \bar{e})^2} \]
and the naïve 90% confidence interval is roughly
\[ (\bar{e} - 1.6 \cdot \widehat{SE}, \bar{e} + 1.6 \cdot \widehat{SE}) \]
In our running example, the CV estimate of generalization error for the quadratic model is about $320,000, so it looks like we can meet the bank’s requirement, no problem, but the 90% confidence interval goes all the way up to $353,000. So we cannot say our model’s generalization error is definitely less than $350,000, i.e. we cannot meet the bank’s requirement.
One thing to keep in mind; the CI for generalization error is not the same as a prediction interval, which is the range of plausible target values for a specific input feature point. The generalization error CI is the range of plausible values for the average model prediction error.
Cross-validation is a surprisingly strange beast
A final bit of background. Back in 2009, ESL pointed out that it’s better to think of CV error as estimating the average generalization error over many hypothetical datasets (and trained models) that we could have drawn from the same underlying data generating process, not the generalization error for the dataset and model we actually have in-hand. As that book says in section 7.12:
…estimation of test error for a particular training set is not easy in general, given just the data from that same training set. Instead, cross-validation and related methods may provide reasonable estimates of the expected error…
As a practitioner, this is disconcerting, to say the least. It doesn’t help much to know the average prediction error over all possible datasets I could have; I need to know the generalization error for the dataset I do have. ESL shows this through simulations but does not go into much detail about why this is the case.
What does the paper show?
Bates, et al. show four main things in Cross-validation: what does it estimate and how well does it do it?.
The naïve way to compute the standard error of the CV estimate of generalization error yields confidence intervals that don’t trap the true generalization error with the intended frequency. A 90% confidence interval, for example, might only trap the true generalization error 60% of the time. This would be a problem for our hypothetical farmland appraisal model, for example. Imagine we promised the bank that our model’s average prediction error was below $350,000 with 90% confidence, but in reality our estimator only trapped the true error with 60% frequency. We could be in big trouble.
The paper proposes a new nested cross-validation algorithm to construct confidence intervals for generalization error that do cover the true error more frequently.
Bates, et al. prove that CV error has larger variance as an estimator of generalization error than it does as an estimator of the average generalization error across many hypothetical datasets drawn from the same generating process. The authors present this as their primary result, but I think the confidence interval result and algorithm are more relevant. This principle was discussed in ESL, but Bates, et al. prove it for the case of linear models.
Simple data splitting with re-fitting is not a short-cut around these issues. Estimating generalization error on a final test set is great if you have lots of data, but in small-data settings, we sometimes re-fit the final model to the whole dataset.6 If we need an accurate point estimate or confidence interval for generalization error, this is a bad idea.
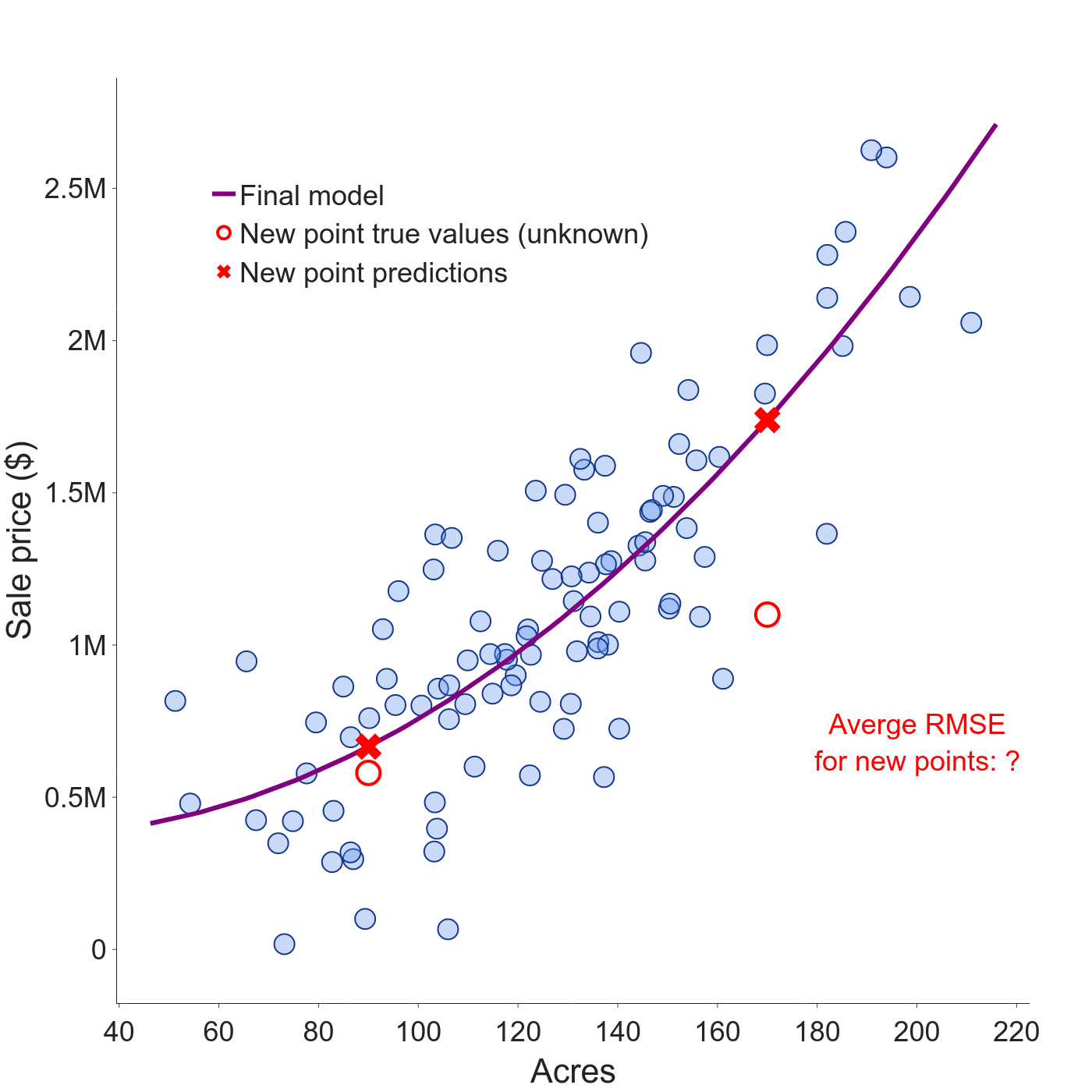
The paper also reports a secondary result that is interesting as a thought experiment. Imagine we have our farm value dataset and another hypothetical draw of just the target variable at the same feature points. Bates, et al. show that CV with the hypothetical dataset would be just as good as CV with our actual dataset at estimating the generalization error. Kind of mind-blowing to think that the data we have in hand is no better than hypothetical data; it accentuates the point that CV doesn’t do a good job of estimating what we want.
The results in this paper need to be taken with a big pile of salt because they apply to only a very narrow set of circumstances.
The data must be identically and independently sampled—no grouping or time dependence.
The proofs apply only to linear models fit with least squares.
Some proofs are based on the idea that the number of data points and the number of features grows infinitely. I find it hard to imagine a real-world situation where this applies.
The dataset is small, presumably because this is when CV is most useful. The paper demonstrates results on simulated datasets with only 50-200 observations and real datasets with only 50-100 observations.
The estimator for generalization error is linearly invariant. I have no intuition whatsoever for this, but the authors reassure us that most common estimators have this property.
What does it mean for my applied data science work?
Not much, to be honest, at least for now. In addition to the very narrow conditions required by the proofs, there seem to be some big conceptual gaps between the research and applied practice. All the same, it’s worth reading, even for applied data scientists.
Reactions
First, the big picture. Industry data scientists have realized over the past few years that random data splitting and cross-validation are rarely useful in practice because time matters in the real world. Our training data set was collected in the past but our model will be deployed in the future, so a realistic estimate of generalization error requires a temporal split. As the scikit-learn user guide says
While i.i.d. data is a common assumption in machine learning theory, it rarely holds in practice. If one knows that the samples have been generated using a time-dependent process, it is safer to use a time-series aware cross-validation scheme.
Even for our simulated farm value example, I would at least compare the results from a temporal split vs. k-fold CV. With a real land value dataset, I’m almost certain the temporal split would be more appropriate.
A second factor limiting the Bates et al. paper’s practical relevance is the narrow set of technical conditions required to make the proofs work. What I’m most confused about is that most of the proofs require the number of observations and the number of features to grow infinitely, but CV is most useful in a small data setting, when simple data splitting is unreliable and too detrimental to model performance. This seems to be a fundamental contradiction and I’m not sure what to make of it.
In their discussion, the authors surmise that their results may apply sort of proportionally to the extent which their assumptions hold. Specifically, given a fixed number of a features, the larger the number of observations, the more accurate the naïve standard error estimator is. Same for regularization; the weaker the model’s complexity penalty, the more the results in this paper matter.
Recommendations
Despite its limitations, this paper has several important takeaways for professional industry data scientists:
It is a great reminder to re-read ESL chapter 7 on model assessment and some of the more recent papers cited by Bates, et al. There are many surprising things about model assessment that are easy to forget in the hustle of industry practice.
Neither industry practitioners nor academic sources seem to worry much about the rationale for model assessment, but we should. Particularly if bad predictions can be catastrophic—as in medicine, finance, insurance, or flight control systems, for example—we need to understand the distribution of model errors. In these cases, the question may not be which model is best, but is any model acceptably accurate at all?
If the assumptions of Bates, et al. do apply to your business problem, then consider trying their nested CV method for the generalization error confidence interval. Admittedly, most data science problems in industry today have plenty of data, so simple train-validation-test set splits should suffice.
As this research topic gathers momentum, more results will be found. Be on the lookout and be open to updating your model evaluation procedures.
It’s both exciting and unsettling that foundational and universal concepts like estimating generalization error are still areas of active research. We should expect that as our theoretical understanding evolves, our ideas about best practices will too.
Footnotes
A quick scan of various data science forums yields endless examples of questions about estimating predictive model performance.
- How (and why) to create a good validation set, by Rachel Thomas
- How to Train a Final Machine Learning Model, by Jason Brownlee
- How to correctly split unbalanced dataset, from the fast.ai forum
- When does stratified k-fold cross-validation provide worse performance than standard k-fold?, from the r/machinelearning subreddit.
- Model evaluation via k-fold-cross validation after variable selection, from the r/statistics subreddit
- Cross validation strategy when blending/stacking, from the Kaggle forum
Data splitting is the term used by the Bates, et al. paper. I haven’t seen it elsewhere, but it’s a good description, so let’s go with it.↩︎
The proliferation of synonyms for generalization error is just ridiculous. Nadeau and Bengio use generalization error, Bayle, et al. use test error, ESL uses expected prediction error, Bates, et al. use out-of-sample error, Wasserman uses prediction risk, Murphy uses population risk. Even more confusingly, some sources use the term generalization error to mean the gap between the population risk and the empirical risk.↩︎
Maybe this is why researchers and data scientists alike tend to focus on model selection and ignore model assessment.↩︎
Murphy, for one, recommends re-fitting the model to the full dataset in section 4.4.4 Picking the regularizer using a validation set.↩︎