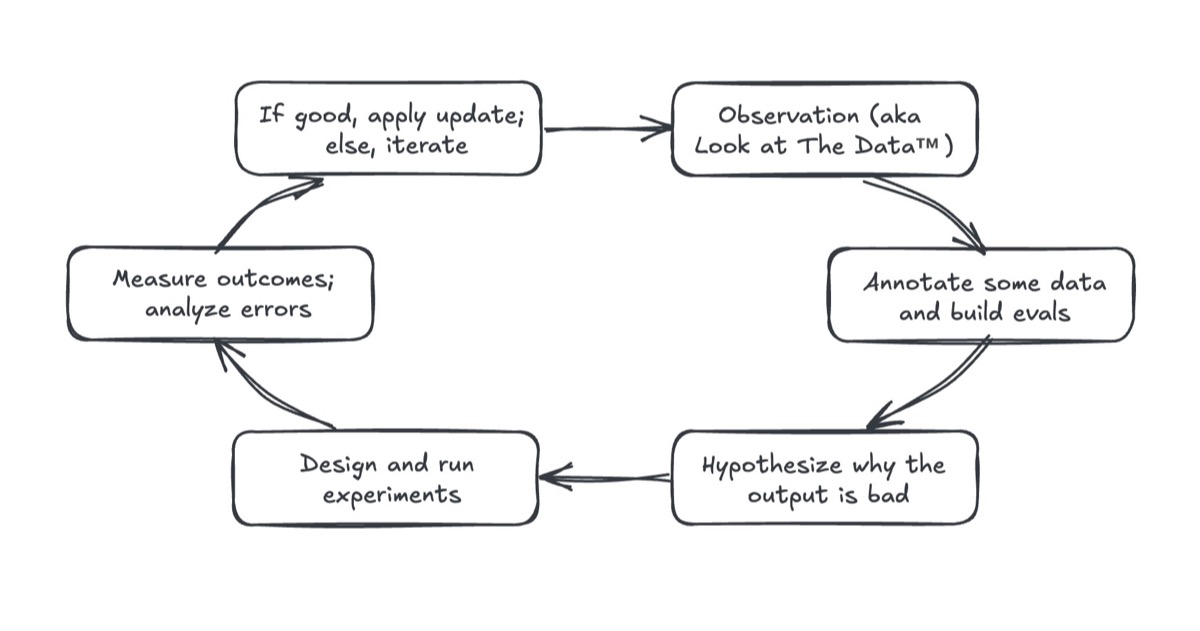
A DSPy footgun
AI Engineering
Python

How to use an LLM to generate SQL queries
AI Engineering
SQL
Python





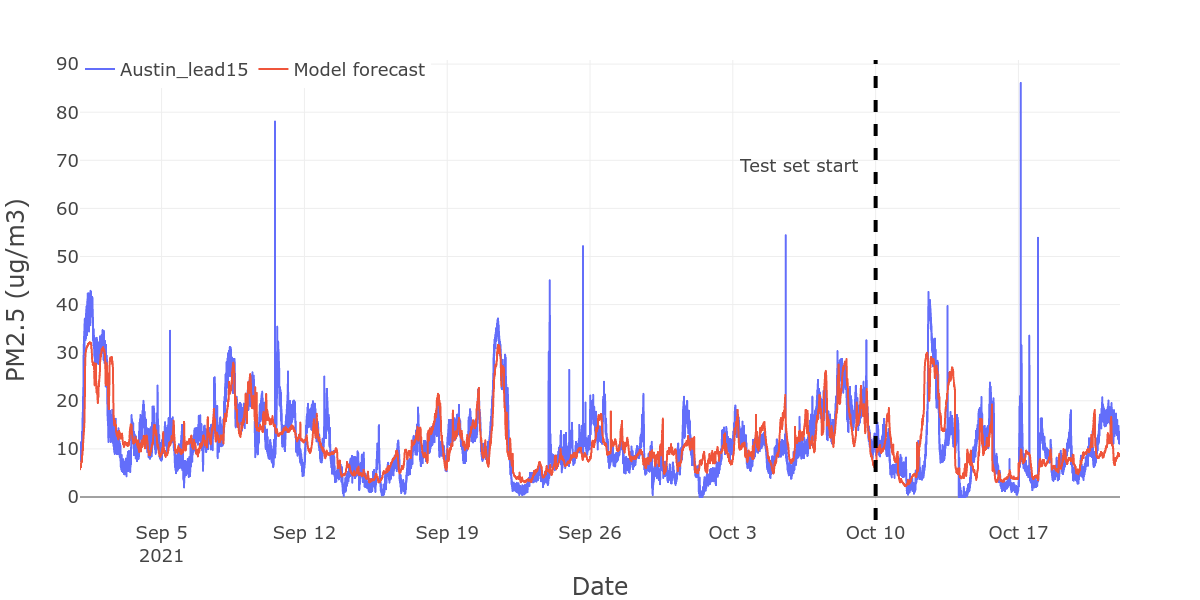
How to use PyTorch LSTMs for time series regression
Python
IOT
time series
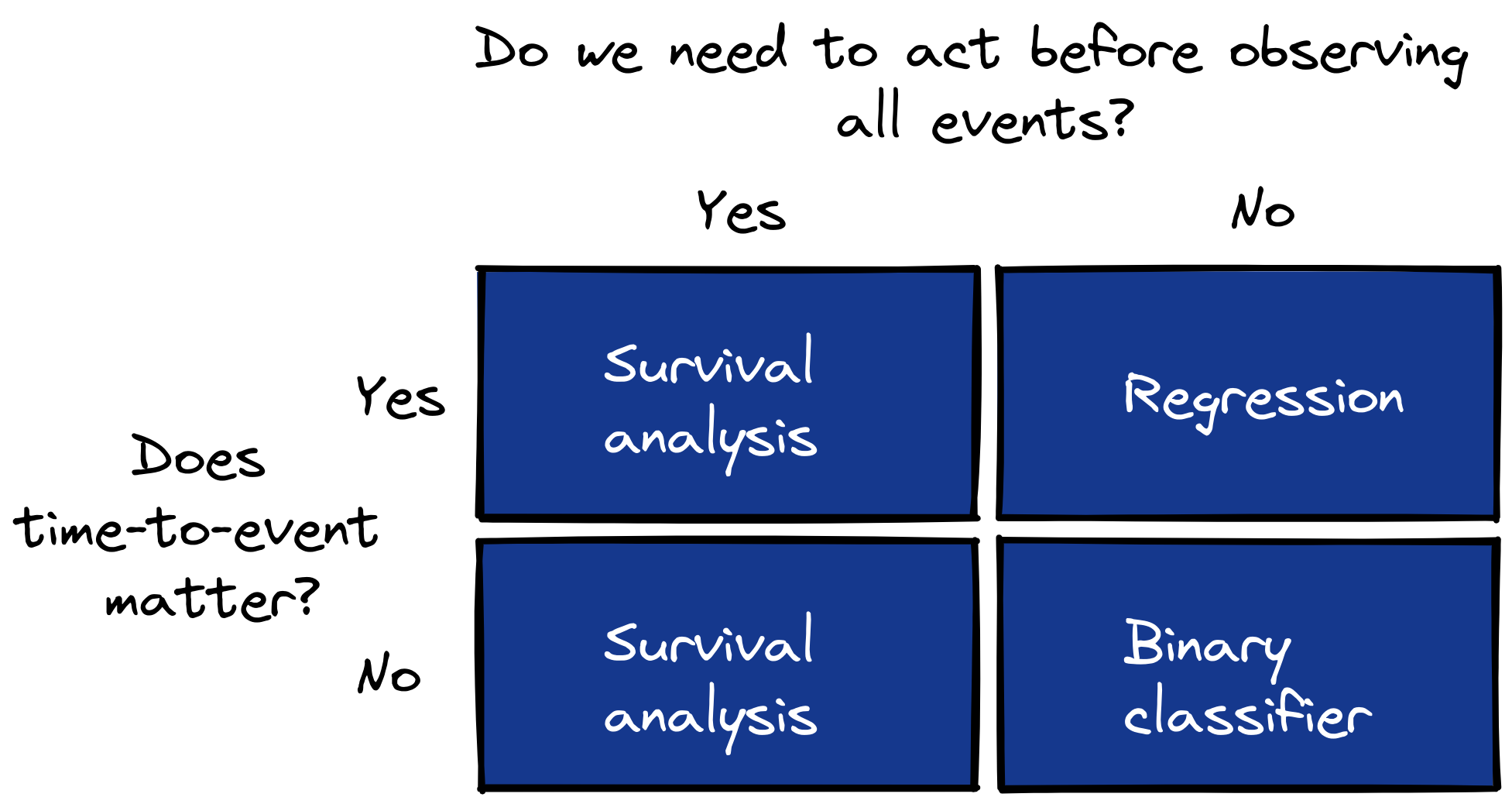
Applications of survival analysis (that aren’t clinical research)
survival analysis

How to compute Kaplan-Meier survival curves in SQL
SQL
survival analysis

How to construct survival tables from duration tables
Python
survival analysis

A review and how-to guide for Microsoft Form Recognizer
reviews
information extraction

A review and how-to guide for Amazon Textract
reviews
information extraction
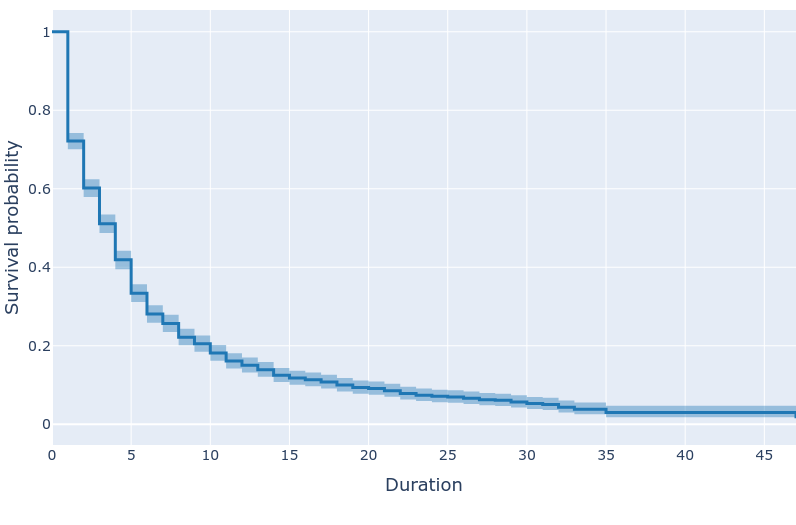
How to plot survival curves with Plotly and Altair
Python
survival analysis

Google Form Parser, a review and how-to
reviews
information extraction

How to build duration tables from event logs with SQL
SQL
survival analysis

How to convert event logs to duration tables for survival analysis
Python
survival analysis

Streamlit review and demo: best of the Python data app tools
Python
data apps
reviews
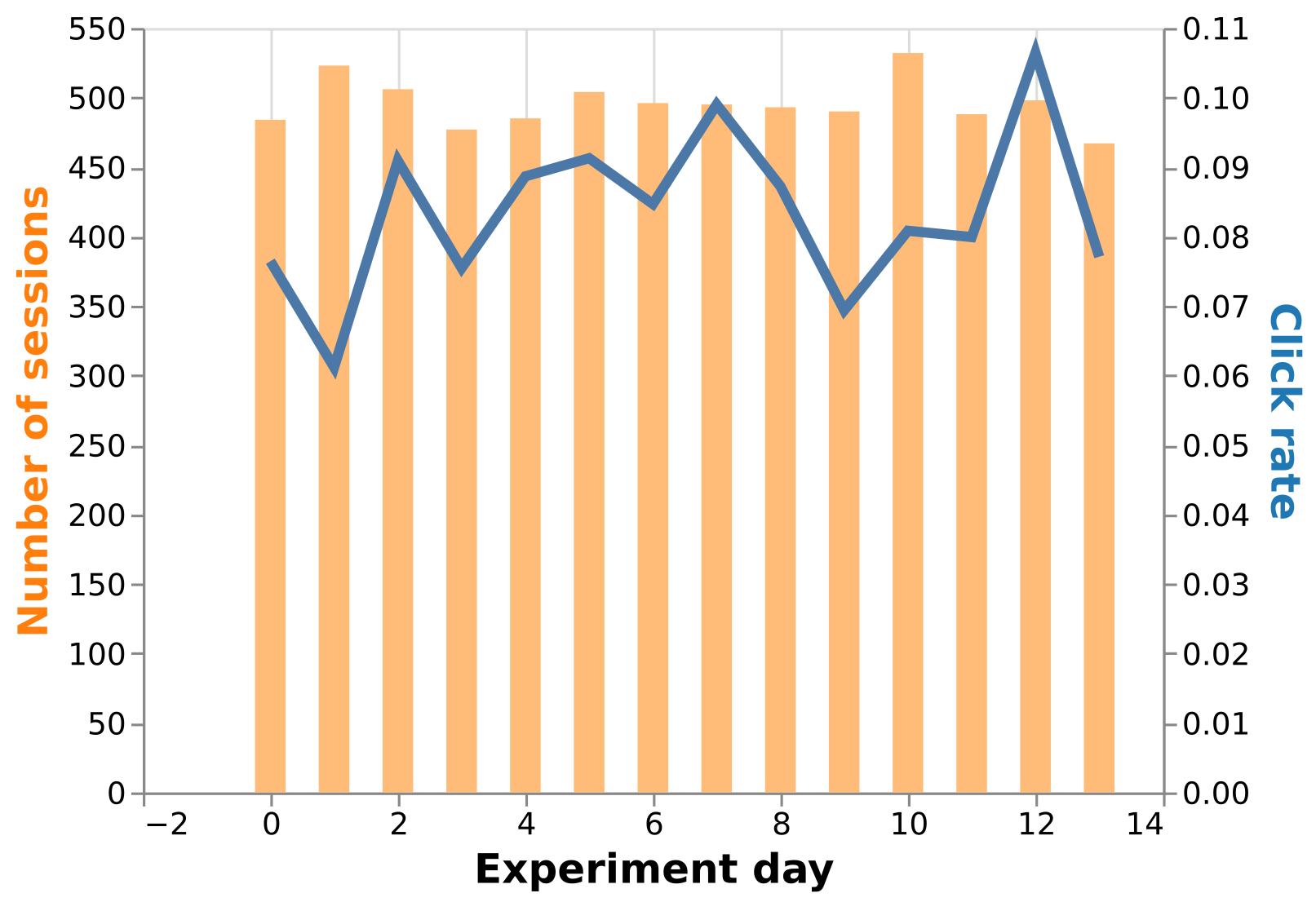
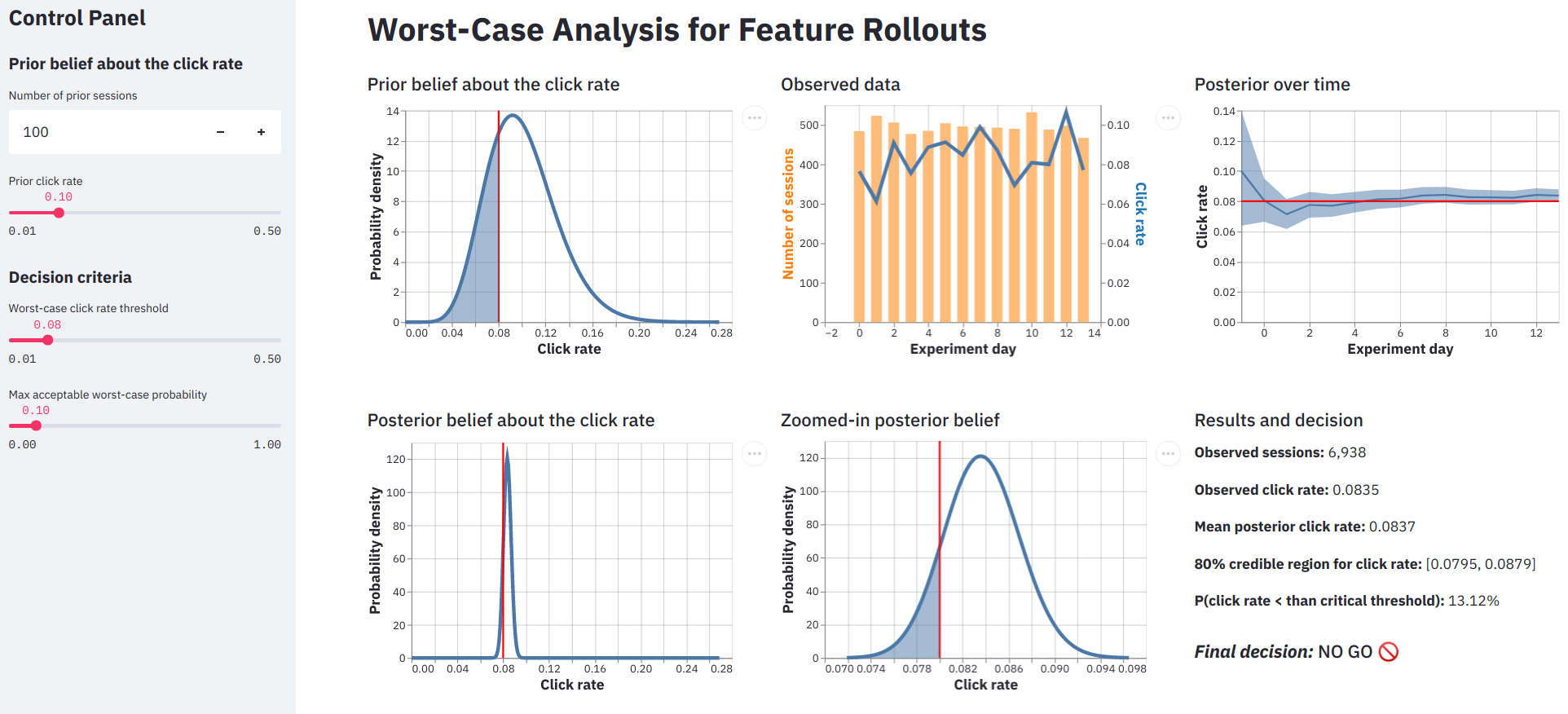
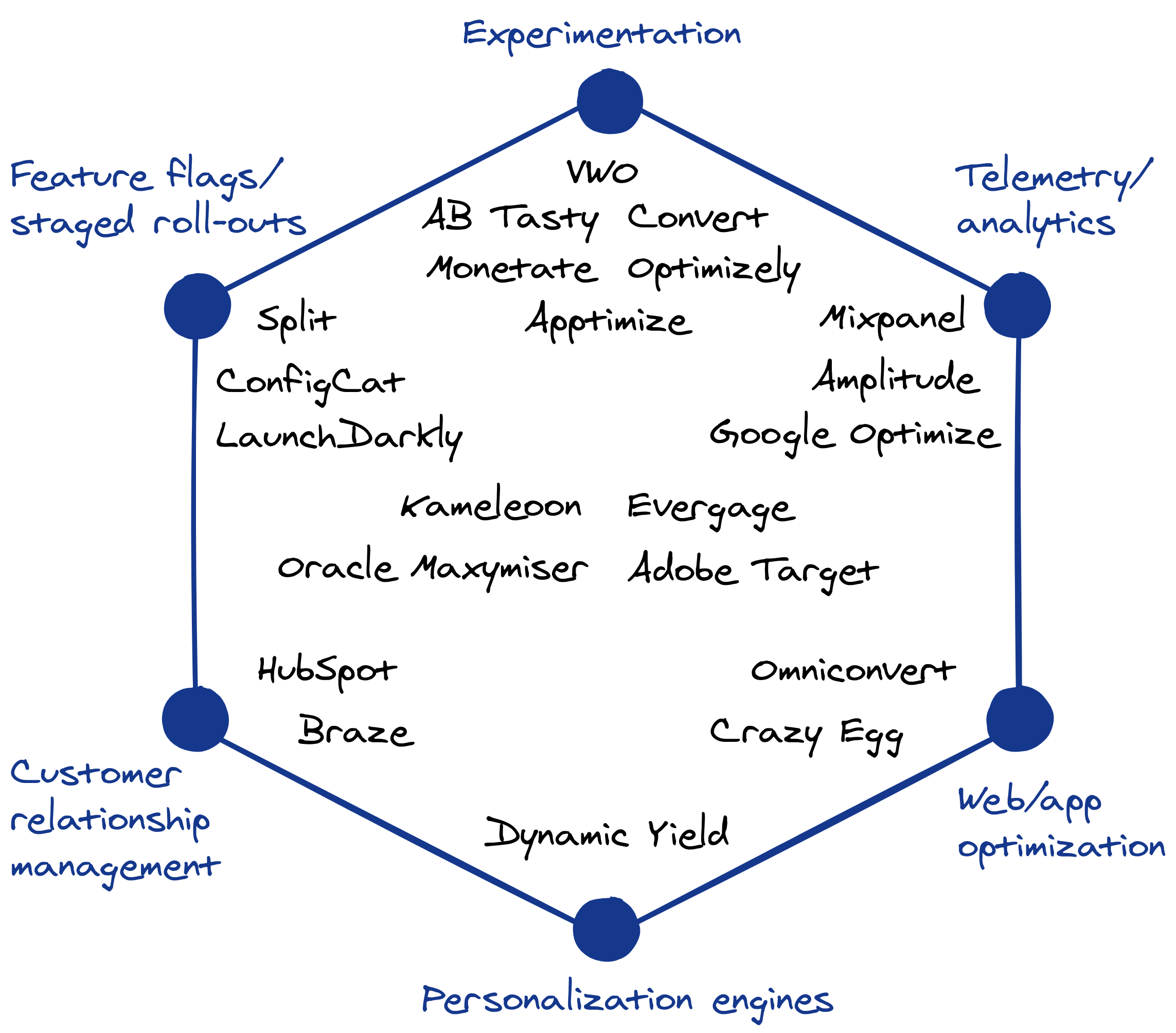
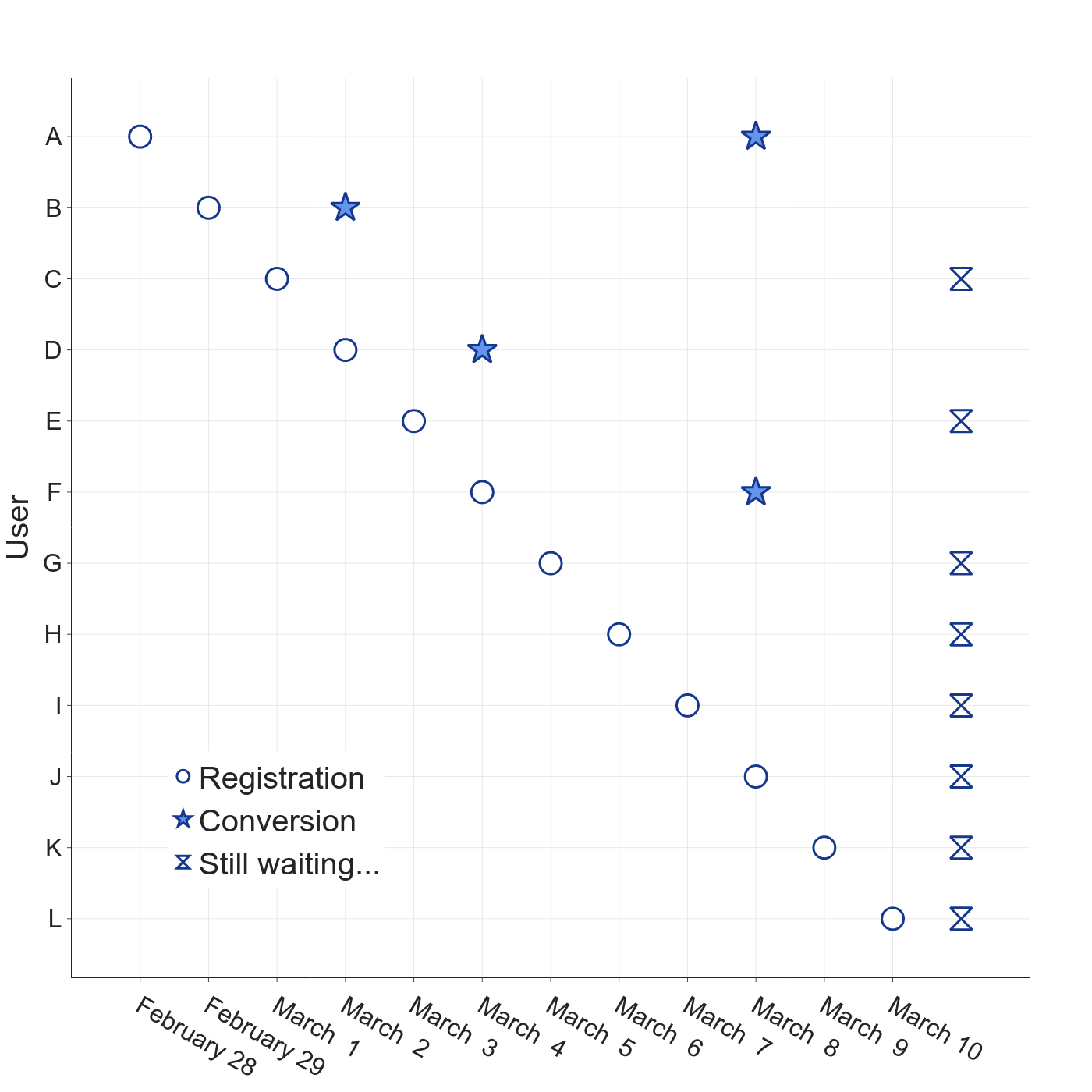
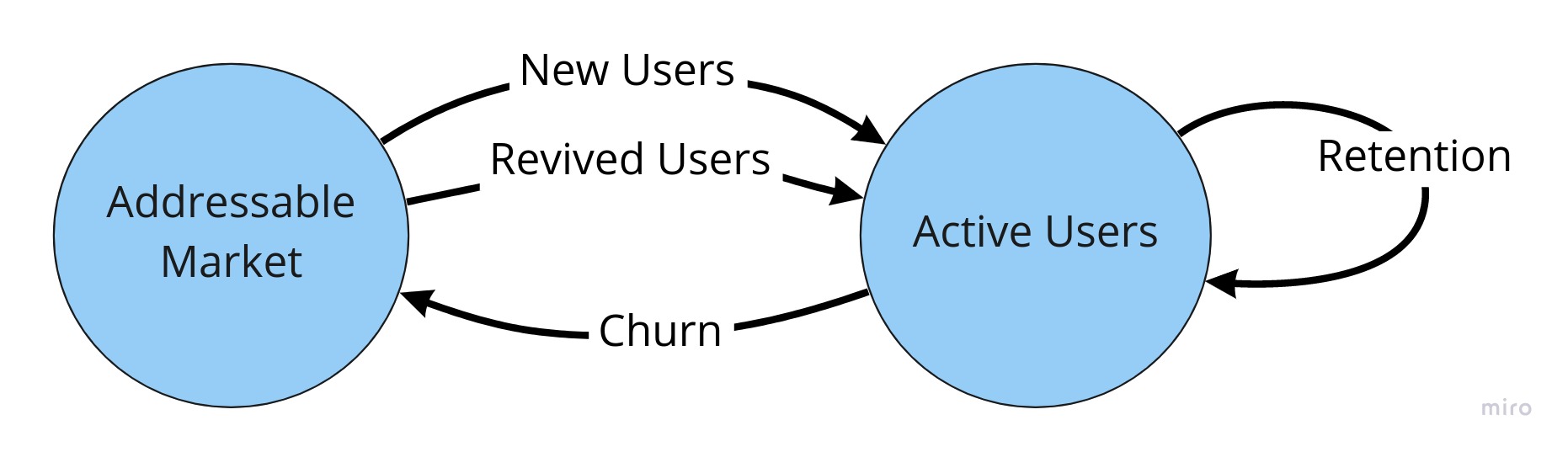
How to analyze a staged rollout experiment
experimentation
Python
data apps
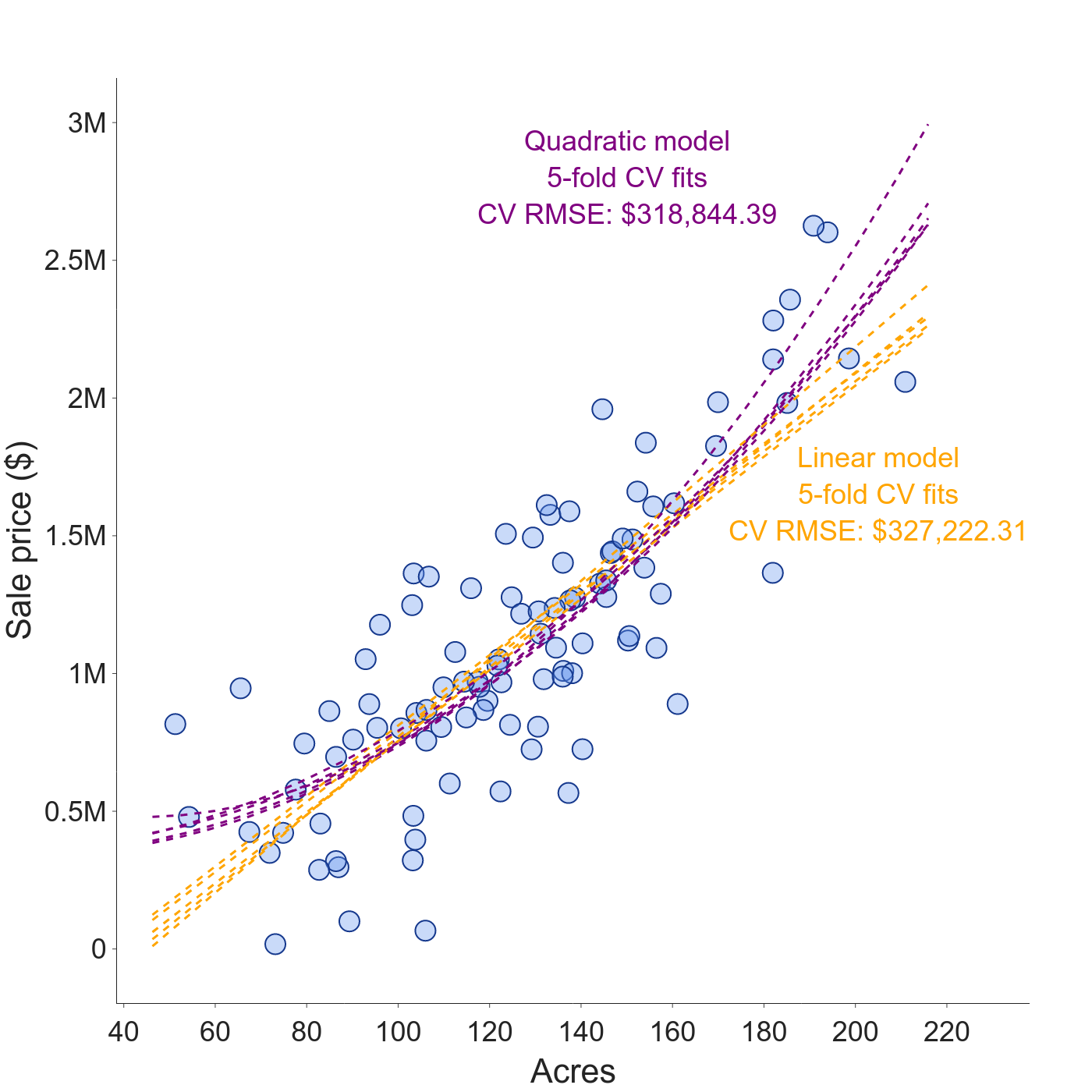
Research digest: what does cross-validation really estimate?
model evaluation

No, your confidence interval is not a worst-case analysis
experimentation
statistics


No matching items