Most intros to LSTM models use natural language processing as the motivating application, but LSTMs can be a good option for multivariable time series regression and classification as well. Here’s how to structure the data and model to make it work.
Python
IOT
time series
Author
Brian Kent
Published
October 27, 2021
Warning
Readers have reported the data used in this article is no longer available. I am not actively maintaining this work, however, so please treat it “as is”. On a related note, check out my new project at https://theapricot.io!
Many machine learning applications that I’ve come across lately are time series regression tasks, where I want to predict a target variable from several input time series.
Measure or forecast cell density in a bioreactor. Measuring directly is painful but direct proxies are too noisy.
Classify a financial transaction as fraudulent or not based on a customer’s transaction history.
Forecast (and optimize) crop yield based on a network of water, sun, and nutrient sensors.
I wanted to try LSTM models with these kinds of problems but found it tough to get started. Most LSTM tutorials focus on natural language processing, to the point where it can seem like LSTMs only work with text data. Searching for “LSTM time series” does return some hits, but they’re…not great.
So here’s my attempt; this article shows how to use PyTorch LSTMs for regression with multiple input time series. In particular, I’ll show how to forecast a target time series but once you have the basic data and model structure down, it’s not hard to adapt LSTMs to other types of supervised learning. Here’s the game plan:
Load, visualize, and preprocess the data
Define PyTorch Dataset and DataLoader objects
Define an LSTM regression model
Train and evaluate the model
In the interest of brevity, I’m going to skip lots of things. Most obviously, what’s an LSTM? For that, I suggest starting with the PyTorch tutorials, Andrej Karpathy’s intro to RNNs, and Christopher Olah’s intro to LSTMs. More advanced readers might be wondering:
I thought attention was all I need? What about Transformers?
Why PyTorch instead of Tensorflow or JAX?
Why not try multiple layers in your LSTM? Where’s the hyperparameter tuning? What about rolling test sets?
All good questions…for another article. In the meantime, please see our Github repo for a Jupyter notebook version of the code snippets below.
Goal
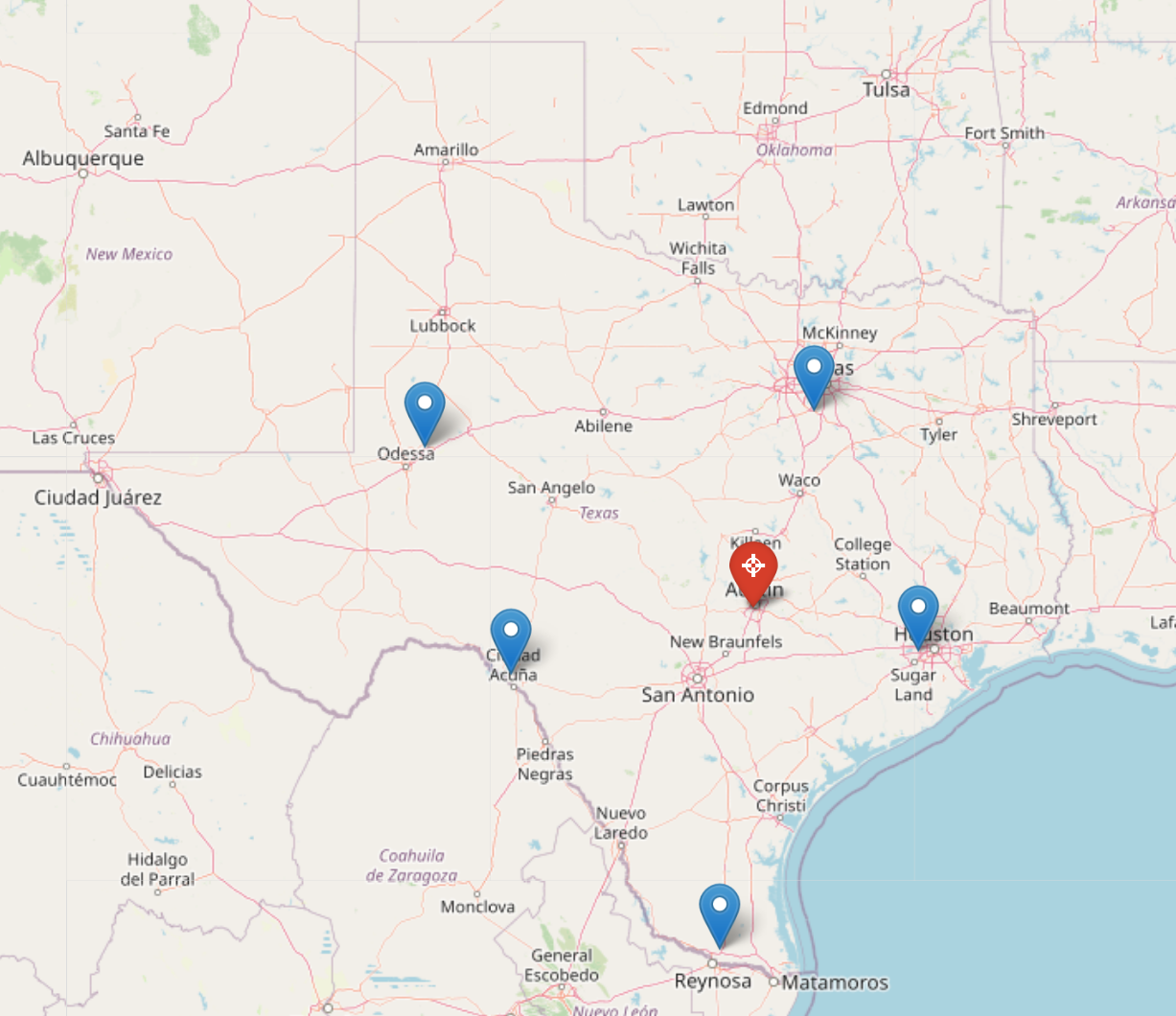
Our goal in this demo is to forecast air quality in Austin—specifically, 2.5-micron particulate matter (PM2.5)—from sensors around the state of Texas.
Why would we do this, when there are plenty of PM2.5 sensors in Austin? Maybe we don’t want to buy a sensor of our own but we have a friend who will let us borrow one for a few weeks to collect training data. Or maybe we need a stand-in for the official EPA sensors when they go offline, which seems to happen often.1
Data
The data come from Purple Air, which sells sensors and makes (participating) customers’ data available for download. I downloaded seven weeks of this data from six sensors around the state of Texas.
Locations of the Purple Air sensors used in this article. We’ll create a model that forecasts the PM2.5 reading at the red sensor in Austin based on the data at the blue sensors around the rest of Texas.
For this demo, I’ve already preprocessed the data to align and sort the timestamps and interpolate a small number of missing values. Please see the preprocess_data.py script in the Github repo for the details. Let’s load the data and visualize it.2
Code
import pandas as pddf = pd.read_csv("processed_pm25.csv", index_col="created_at")print(df)
The columns represent sensors and rows represent (sorted) timestamps. The values are PM2.5 readings, measured in micrograms per cubic meter.3
Plotting all six time series together doesn’t reveal much because there are a small number of short but huge spikes. The second plot is zoomed in to a y-axis range of [0, 60]; it shows clear long-run correlations between the sensors but lots of short-run variation both between and within the series. In other words, an interesting dataset!
Pardon a bit of Plotly styling boilerplate up front.
Code
import plotly.express as pximport plotly.graph_objects as goimport plotly.io as piopio.templates.default ="plotly_white"plot_template =dict( layout=go.Layout({"font_size": 18,"xaxis_title_font_size": 24,"yaxis_title_font_size": 24}))fig = px.line(df, labels=dict( created_at="Date", value="PM2.5 (ug/m3)", variable="Sensor"))fig.update_layout( template=plot_template, legend=dict(orientation='h', y=1.02, title_text=""))fig.show()