Causal Inference: The Mixtape
Scott Cunningham, 2021

Learning causal inference has been frustrating for me; it often feels like a haphazard wandering from book to book, learning conceptual frameworks like potential outcomes and causal graphs without ever developing tools to solve real problems. Scott Cunningham felt similarly, so he wrote this book. Talking about the book’s purpose, Cunningham says (p. 5):
a readable introductory book with programming examples, data, and detailed exposition didn’t exist until this one. My book is an effort to fill that hole, because I believe what researchers really need is a guide that takes them from knowing almost nothing about causal inference to a place of competency.
Causal Inference: The Mixtape covers both major (quantitative) philosophies of causal inference—directed acyclic causal graphs and potential outcomes—as well as six study designs:
- matching
- regression discontinuity
- instrumental variables
- panel data
- differences-in-differences
- panel data
- synthetic control
Each topic spans 30-100 pages, covering historical context, intuitive walk-throughs of examples, detailed proofs of important theorems, and runnable code snippets. Cunningham’s perspective as an economist gives the material a more relatable flavor than most methodological treatments. As an example, he emphasizes that the primary reason why we need causal inference is that humans make choices to optimize their own outcomes. This seems especially relevant to industry data science, where our work is often meant to understand and affect human behavior.
The flip side of Cunningham’s engaging example- and story-oriented writing style is that despite being over 500 pages long, the book doesn’t feel useful as a reference. It’s hard to look up specific bits of information, and there is a lot of extraneous information. If you want to look up the key assumptions of the differences-in-differences method, for example, you’d be better off with Emily Riederer’s Causal Design Patterns article. But if you want to spend a lazy Saturday morning learning everything there is to know about differences-in-differences, then this is the book for you.
The book is available online for free. This is most helpful for the code snippets (in R, Stata, and Python), which are tedious to transcribe from the book. I paid for the hard-copy book because I think the information is worth the price and because books are a more effective reminder of my to-read list.
You’re probably measuring your treatment effect incorrectly
Chris Said, March 28, 2021
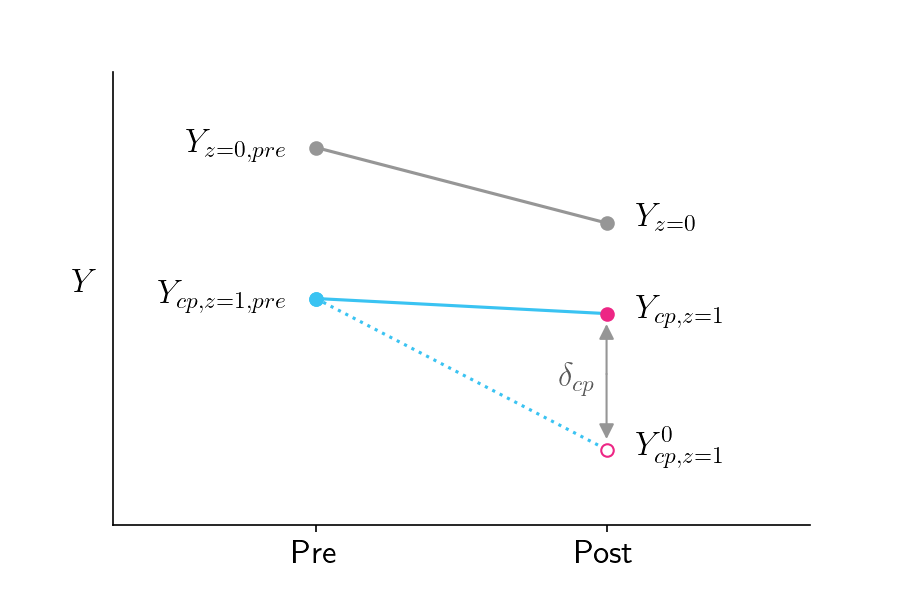
This blog post is what reminded me to return to Causal Inference: The Mixtape. Said’s article is fantastic: short and to the point, the figures are clean and effective, and I learned something slightly mind-blowing in just a few minutes of reading.
Specifically, Said describes the Local Average Treatment Effect (LATE), which is the effect of a treatment on those who actually received the treatment. Contrast this with the Intention To Treat (ITT) effect, which is the difference in outcomes between the group assigned to receive the treatment and those assigned to the control group.
This is relevant, of course, when treatment compliance is an issue. Said doesn’t motivate the post with examples, but treatment compliance comes up all the time, especially in industry data science where experiment subjects are often people. Say, for example, our company recently launched a new credit card and we want to know how using that card affects users’ credit health. We can’t force users to sign up for the card, let alone use it; the best we can do is randomize who has access to the card. As Said shows, we would need to compute the LATE, not the ITT, and definitely not the difference between those who choose to use the card and those in the control group.