A collection of interesting things I’ve read over the past month. Emphasis on how to evaluate LLM-powered systems.
Evaluating LLM-powered systems
Ben Recht
Evaluation or Valuation (April 2025)
- Because tests are built from natural language, a tool that perfectly interpolates enormous training sets of natural language will of course do well on test sets of yet more natural language. These benchmarks don’t really give us estimates of generalization performance. Or rather, what does “generalization” even mean any more when the model is trained on effectively all langauge? To use Recht’s words (bold mine): “I think we’re finally coming to terms with the fact that we have no idea how to use machine learning benchmarking to evaluate LLMs.”
- To Recht, choosing between SOTA LLM chatbots is now closely akin to choosing between traditional productivity software. It’s more about ease of use, stickiness, and (presumably) distribution than performance on quantitative benchmarks.
My take:
Maybe our benchmarks are bad because there’s very little overlap between LLM research skills and taste-oriented endeavors. Oenophiles, for example, have developed an extensive (and often mocked) system for testing and talking about how wine makes them feel, while LLM connoisseurs are stuck on vague “vibes” and unhelpful academic benchmarks.
TIL: Moravec’s paradox: in short, skills like reasoning that seem intuitively complex are surprisingly computationally simple.
Vikram Sreekanti & Joseph E. Gonzalez
Building AI applications you can trust (April 2025)
- Until recently, the UX for AI applications has been poor and people haven’t paid much attention to it. Going forward, control and visibility are the key dimensions to emphasize in improving UX.
My take:
What do Sreekanti and Gonzalez mean by an “AI application”? Is it a general purpose chatbot, e.g. ChatGPT or Claude? Or is it a tool for end-users powered under the hood by calls to an LLM API? Control and visibility are probably key UX dimensions in every domain, but I suspect only LLM researchers and app creators want more control and visibility. End users just wants things to work with the least possible cognitive load.
Thinking about different kinds of LLM users got me thinking about a spectrum of LLM trust…from people who refuse entirely to use LLMs on one end to the vibe coders on the other. This seems like a useful dimension for pondering lots of LLM-related things, like “Where should my company or ML/AI team invest our time and attention?”
Eugene Yan
An LLM‑as‑Judge Won’t Save The Product—Fixing Your Process Will (April 2025)
- Eval-driven development, AKA “Building product evals is simply the scientific method in disguise.” Yan describes five steps in this process (the 6th is my addition):
- Look at the data: inputs, outputs, user interactions
- Annotate some data, labeling successes and failures of the system
- Hypothesize why the failures happen
- Run experiments to test the hypothesis
- Quantitatively measure outcomes and decide if the experiment improved them.
- (Repeat)
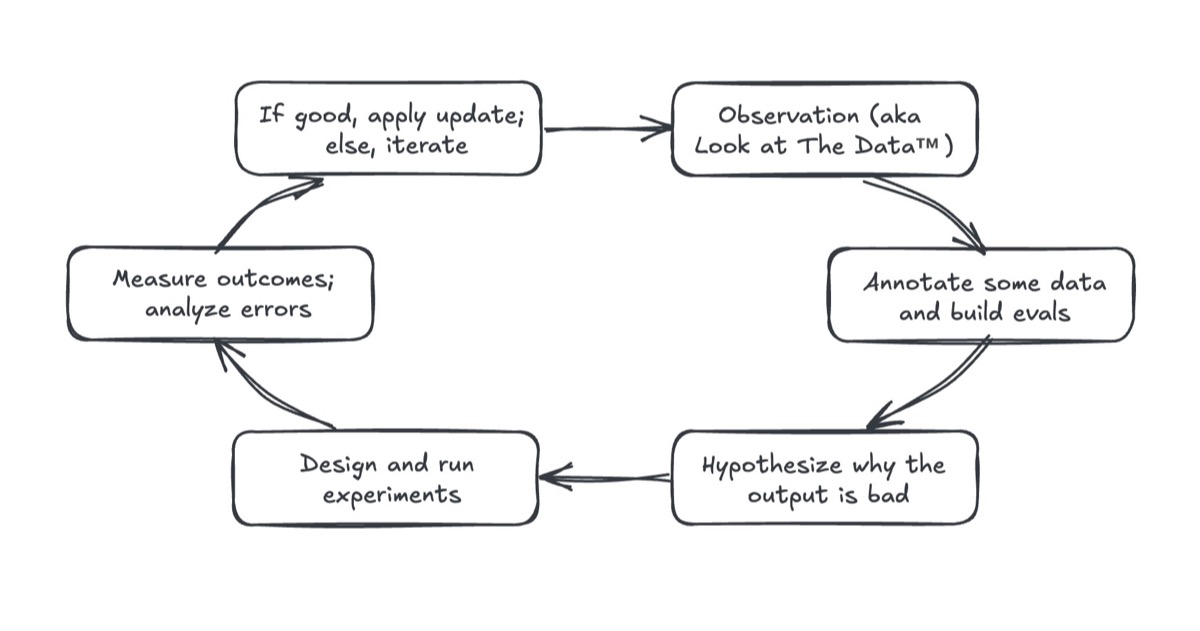
Eugene Yan’s Eval-Driven Development cycle. - Good news! ML teams have been doing similar things all along, in the form of iteratively evaluating model improvement hypothesis against validation and test tests.
My take:
- I’ve been pitching the idea that evaluation has been ML’s secret sauce all along to anyone who will listen. Hopefully Yan’s excellent writing will help the message land. Unfortunately, Yan kind of glosses over the quantitative measurement part, which is the crux of the thing.
Andrew Ng
The Batch, Issue 297 (April 2025)
- Don’t fall into the trap of postponing automated LLM evals indefinitely because it’s hard to do all at once. It’s better to start early, even with a small set of imperfect and incomplete evals, then iterate and grow over time.
My take:
- Makes sense—it shouldn’t be controversial to start with a simple end-to-end system and iterate quickly (but maybe it is). Ng’s advice dovetails with Eugene Yan’s piece (above) but somewhat contradicts Hamel Husain’s advice (below) to stick with human annotators until you build trust in the automated evals.
Hamel Husain
A Field Guide to Rapidly Improving AI Products (March 2025)
- In Husain’s experience, teams who succeed at building AI products:
- Obsess over measurement and iteration, not tools.
- Focus on bottom-up metrics, discovered through structured error analysis, i.e. “looking at the data”.
- Use an integrated prompt environment to let domain experts and admins play with prompts in a modified version of the real UI.
- Use LLM-generated synthetic data to bootstrap evals.
- Treat evaluation criteria as a living, evolving thing.
- Use binary pass/fail evaluations of LLM outputs.
- Measure alignment between human and automated evals
- Emphasize human evaluation early in the project until trust is built in the automated evals.
- Plan and measure progress in terms of experiment cadence, not delivered features.
- In Husain’s view, the most important investment an AI team can make is a simple UI tool for viewing data. This tool should be custom, show all necessary context in one place and give admins a place to write open-ended feedback.
My take:
- Husain to the rescue, just when I was getting tired of the LLM evaluation think pieces and looking for concrete recommendations. If you work with LLMs, you owe it to yourself to the read the post in detail. In fact, AI teams could do worse than adopting piece in its entirety as an operating manual.
Sociology of LLMs
Cosma Shalizi
On Feral Library Card Catalogs, or, Aware of All Internet Traditions (April 2025)
LLMs and related systems are best understood as a cultural technology, i.e. a new way for people to transmit information between ourselves. Shalizi suggests we should think of LLMs like glorified library card catalogs; we don’t fear that card catalogs will develop artificial superintellience so we shouldn’t fear it with LLMs either. There are lots of potential problems with LLMs but it doesn’t help to get spun up about myths of superintelligence.
Shalizi quotes Jacques Barzun, who drew a distinction between intellect, which is “a body of common knowledge and the channels through which the right particle of it can be brought to bear quickly”, and intelligence, which is “an individual and private possession”. Shalizi believes LLMs, like the alphabet, are an example of intellect but not intelligence, or rather that LLMs have learned nearly all of human intellect, but this still does not count as intelligence.
My take:
Thinking only about LLMs, I agree with Shalizi—a tool built to estimate next-token probabilities isn’t scary, no matter how much data it’s trained on. Where I think Shalizi misses, though, is in saying that LLMs aren’t agents because they don’t have beliefs, goals, desires, or intentions. That may be true (or not) but LLM-powered systems very much do have goals. And once those goals are coupled with the entirety of human intellect made accessible in a fast, automated, scalable way, it does start to feel a bit scary.
I think Shalizi underestimates even plain vanilla LLMs’ capacity for creative intelligence and handling unusual situations. He says “[it] sucks to try to use [LLMs] to communicate unusual ideas, especially ideas that are rare because they are genuinely new”, because LLMs are trained to maximize average likelihood. In my own (anecdotal) practice, though, I don’t find this to be true at all. I would challenge Shalizi to explain what is special about biological brains that enables creative intelligence that is not available to modern SOTA LLMs.
Confidence intervals
Julia Rohrer
Why you are not allowed to say that your 95% confidence interval contains the true parameter with a probability of 95% (December 2024)
- Because confidence intervals are a frequentist concept, it’s not valid to make probabilistic statements about a parameter being contained within a given CI. This kind of misinterpretation usually doesn’t matter very much, though, because Bayesian credible intervals with non-informative priors are usually similar to confidence intervals. So confidence interval misinterpretation is mostly a question of language purity; for practitioners, there are no consequences of misinterpretation.
My take:
I wrote something similar a few years ago but came to the opposite conclusion; if the right tool (Bayesian credible intervals) exists for the task, why not use it? For many applications, stakeholders do have an informative prior and the credible and confidence intervals will differ. In fact, letting people play with the prior interactively can be an excellent way to communicate an experiment plan and results.
A solid understanding of how to use (and how not to use) CIs can also help identify fuzzy thinking on the part of stakeholders. I was once asked, for example, if we could use a frequentist CI as a form of “worst case analysis”. Thinking through the statistical interpretation led us to first clarify the business objective, which was ultimately the more important part.
Demetri Pananos also wrote a nice blog post about this topic recently.
Urban mobility
Neha Arora and Ivan Kuznetsov (Google Research)
Introducing Mobility AI: Advancing urban transportation (April 2025)
- A good summary of the last year of research from the Mobility AI team. Digital twins, modeling traffic congestion, parking difficulty, origin-destination matrices, and energy consumption, and optimizing routing stratgies and traffic signals—all to help policymakers address problems with traffic gridlock, environmental damage, and road fatalities.
My take:
Google’s mobility work has to be one of the most under-appreciated research teams, but I can’t help but notice a giant hole… All that great work but not a single mention of a much, much simpler idea…just reduce the number of cars!
reducing cars in cities is an instant boost for mobility, for livability, for public health, for climate
it's absolutely insane that basically ZERO US cities are doing anything to reduce number of cars in their cities
seattle has 60% more cars in 30 years, paris is down by 45%
zero leadership
[image or embed]— Mike Eliason (@holz-bau.bsky.social) April 25, 2025 at 10:51 PM