ML products evolve quickly and this review is likely out of date. It was our best understanding of this product as of July 2021.
To avoid bias, Crosstab Data Science does not accept compensation from vendors for product reviews.
What do driver’s licenses, passports, receipts, invoices, pay stubs, and vaccination records have in common?
They are all types of forms and they contain some of society’s most valuable information. A sprawling marketplace of products has popped up to convert this information into data, a process I call form extraction. I’m interested in particular in general-purpose form extraction tools that can work with any kind of document—not just invoices, receipts, or tax forms—and off-the-shelf services that don’t require any model fine-tuning.
Microsoft’s cloud solution for general-purpose form extraction is Form Recognizer. A few months ago, I put it to the test against Amazon Textract and Google Form Parser on a challenging dataset of invoices. To put it bluntly, Form Recognizer came up short, in terms of ease of use, accuracy, and response time.
Please see our Form Parser and Textract reviews for comparison.
Microsoft Form Recognizer Highlights
| Surprise & Delight | Friction & Frustration |
|---|---|
| Unstructured text extraction is relatively accurate. Building a heuristic key-value mapping with this output is a viable option. | For general-purpose forms, you must train a custom model upfront before extracting any form data. There is no general-purpose fully off-the-shelf service. |
| Low accuracy on average, compared to other services. Training set size is capped at 500 documents, so how to improve accuracy? |
What is form extraction?
Suppose we want to use the information in our customers’ pay stubs, maybe to help them qualify for loans. A pay stub is a form; it is a stylized mapping of fields—let’s call them keys—to values. Take this example from the Gusto blog:
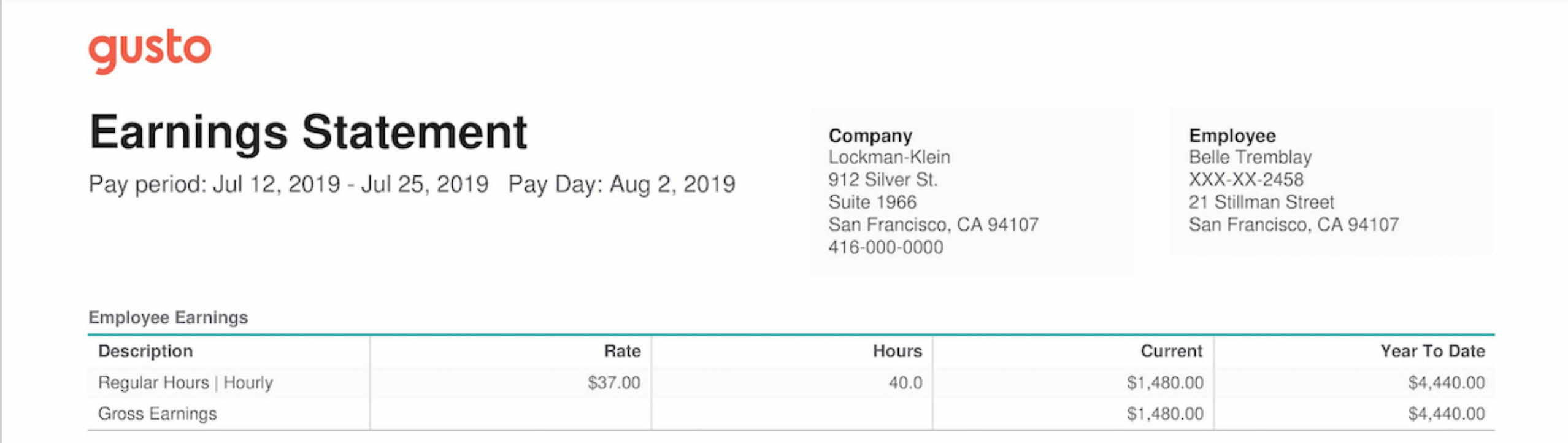
Our brains process this easily but the information is not accessible to a computer. We need the information in a data format more like this:
{
"Pay period": "Jul 12, 2019 - Jul 25, 2019",
"Pay Day": "Aug 2, 2019",
"Company": "Lockman-Klein",
"Employee": "Belle Tremblay",
"Gross Earnings": "$1,480.00"
}It’s helpful to step back and contrast this with two other information extraction tasks: optical character recognition (OCR) and template-filling. OCR tools extract raw text from images of documents; it is well-established technology but only the first step in capturing the meaning of a form.
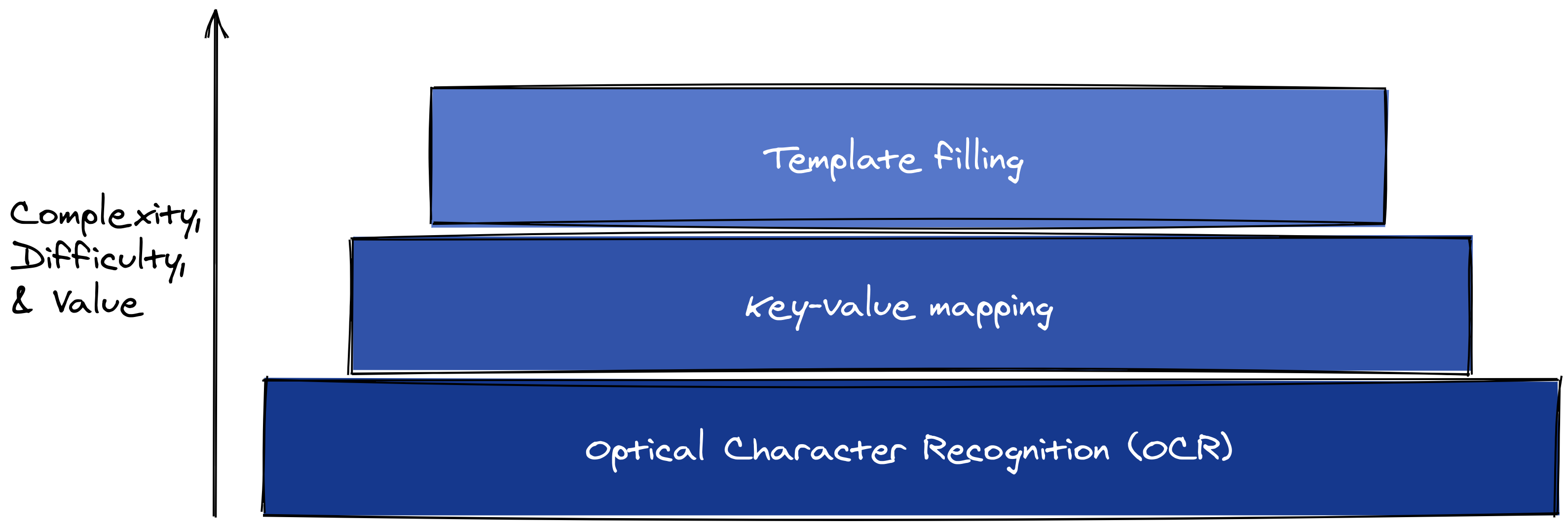
Template-filling, on the other hand, is the holy grail; it seeks to not only extract information but slot it correctly into a predetermined schema. So far, template filling is only possible for some common and standardized types of forms like invoices, receipts, tax documents, and ID cards.1
Key-value mapping is in the middle. It’s easier than template-filling, but still hard. The Gusto demo shows why:
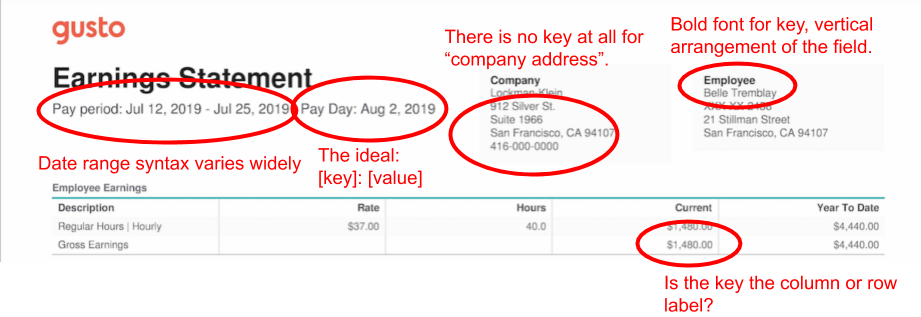
Some values have no keys. Others have two keys because they’re in tables, where the row and column labels together define the field, even though they’re far apart on the page.
The association between key and value depends on a subjective reading of page layout, punctuation, and style. Some keys and values are arranged vertically, others horizontally. Some keys are delineated by colons, others bold font.
Manually specifying field locations and formats is a non-starter because form layouts and styles vary across processors and across time. It’s not just pay stubs; US driver’s licenses, as another example, vary across states and time. Medical record formats differ between providers, facilities, and database systems.
Microsoft Form Recognizer on paper
Ecosystem
According to this April 2021 ZDNet article, Microsoft Azure is a “strong” number two cloud infrastructure provider, behind Amazon Web Services. As such, I have no concern about the completeness and stability of Azure’s data and machine learning product lineup. In fact, Microsoft has done a better job than competitors at issuing frequent updates to Form Recognizer and documenting those updates well.
On the other hand, Azure can be more confusing to navigate than other cloud platforms, in my opinion. For example, I still can’t figure out how to initialize a new Form Recognizer endpoint by browsing from the main Azure portal. Form Recognizer is currently part of Applied AI Services but in my account, it’s listed as part of Cognitive Services (which is supposedly a different thing). Following that lead, I expected starting a new Cognitive Services resource would create a new Form Recognizer endpoint, but it seemed to be a dead-end. Instead, I used the links from the Form Recognizer documentation or searched from the portal main page.
In the end, though, Azure’s functionality is essentially on par with other platforms, and climbing the learning curve is a one-time cost.
Features and limitations
Form Recognizer’s features, limits, and quotas are roughly the same as its competitors, with one major exception. Unlike Amazon and Google, Microsoft does not have a pre-built model for generic form extraction; if you want to get form data out of a document that’s not an English-language receipt, invoice, ID, or business card, you must train a custom model.
Model training can be unsupervised, which avoids the hassle of labeling documents with ground truth (presumably at the expense of model accuracy). You still have to worry about model management and training experiment tracking, though, which is a major undertaking. If your team can deal with model management well, you likely also can train and deploy custom form extraction models without any help from Microsoft.
What’s even more bizarre about Microsoft’s product decision is that the training set cannot exceed 500 total pages. I did a Patrick Stewart-style quadruple take when I read that, but it’s not a joke; here’s the exact wording:
The total size of the training data set must be 500 pages or less.
It’s not at all clear to me how the user is supposed to build a high-performance model with only 500 pages of unlabeled forms.
Other hard requirements:
The Form Recognizer service is synchronous by default, at least in the Python client we used. There are code samples that show how to use Python’s
async/awaitfunctionality to treat the API as asynchronous.The API accepts both image and PDF files (as well as TIFF), up to 50 MB and 200 pages (for PDFs). Page dimension limits seem reasonable (10K x 10K pixels for images, (17 x 17 inches for PDFs).
I cannot find any information specific to Form Recognizer about rate limits and quotas; presumably, generic Azure limits apply.
Cost
Form Recognizer’s custom model is priced at 5 cents per page, which is on par with Amazon Textract and cheaper than Google Form Parser (6.5 cents/page).
Data policies
The security page for Form Recognizer emphasizes that input data is not used to improve Form Recognizer models, that you can use containers to control where Form Recognizer executes on your data, and that Form Recognizer comes with all of the other guarantees provided by the Azure Cognitive Services platform.
Developer experience
In general, I think the Form Recognizer documentation is quite good. It’s clear about where total beginners should start, has lots of examples and sample code, and thorough, detailed API documentation for the REST endpoints and client SDKs.
One disappointment in the documentation—especially compared to Textract and Form Parser—is that there isn’t a simple point-and-click demo of the service on the Form Recognizer website. It looks like there is because each pre-trained model has a link in the documentation overview that says “Try Form Recognizer” but those links don’t really take you to a demo. They launch a GUI tool that expects you to already have a running Form Recognizer service in your Azure account.
There are 5 main steps to using Form Recognizer for general-purpose documents (i.e. not receipts, invoices, or business cards):
- Set up the Form Recognizer service.
- Create an Azure storage container and upload your training documents.
- Train a custom model.
- Extract data from new documents.
- Convert the extracted data into a usable form.
Follow the quickstart for step 1, to set up the Form Recognizer service and get a custom endpoint and API key. This page steps through the process of creating a training set in an Azure storage container.
Step 3 is where I’ll pick things up; it’s the one that makes Form Recognizer different from Textract and Form Parser. As I mentioned above, Microsoft does not have a general-purpose, off-the-shelf model for documents that aren’t receipts, invoices, IDs, or business cards, so we have to train a custom model.
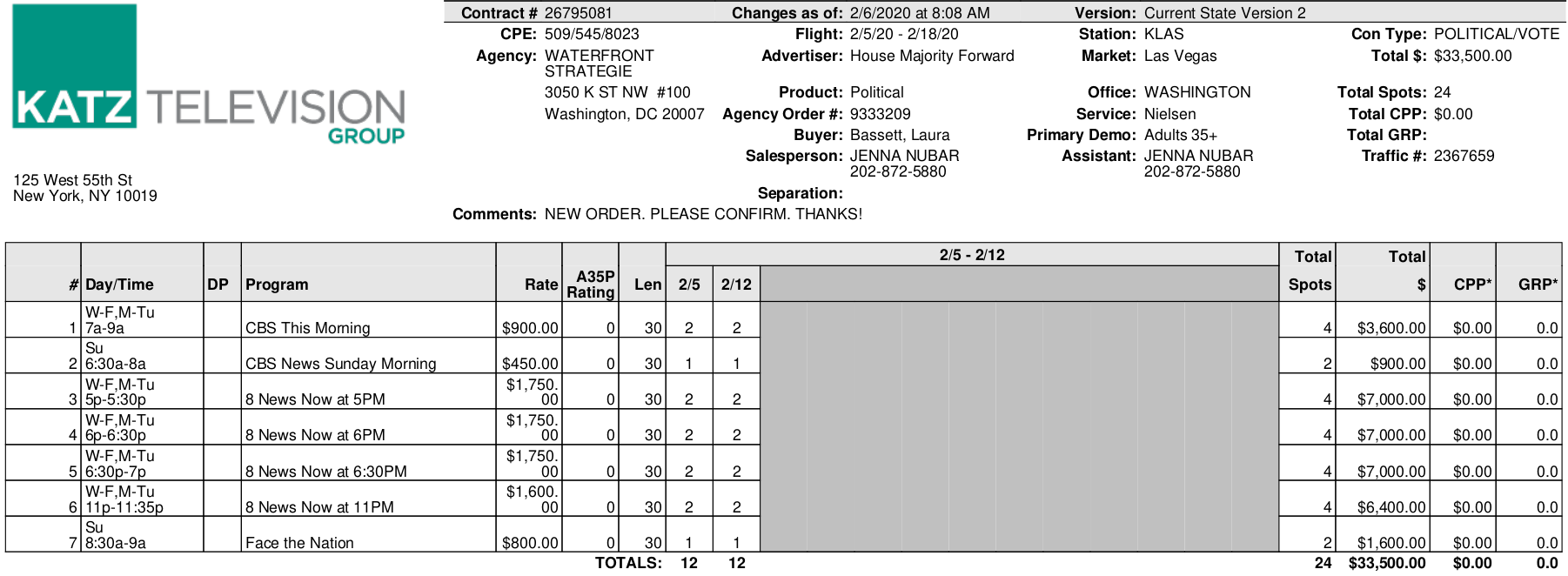
Suppose we want to parse this PDF invoice (yes, I know I could use the pre-trained model for invoices, but I’m interested in the results for documents other than invoices, like pay stubs):
Once the training documents are uploaded, unsupervised training is pretty straightforward. In Python2, we use the FormTrainingClient class and just point it to the container where the training set lives. If this container is not public, you’ll have to create a SAS key and append it to the URL.3
Because I’m not providing training labels, I set use_training_labels to false in the begin_training function.
from azure.ai.formrecognizer import FormTrainingClient
from azure.core.credentials import AzureKeyCredential
endpoint = "<<your Form Recognizer service endpoint>>"
api_key = "<<your Form Recognizer API key>>"
docs_url = "<<your Azure storage container URL with training documents>>"
trainer = FormTrainingClient(endpoint, AzureKeyCredential(api_key))
poller = trainer.begin_training(docs_url, use_training_labels=False)Model training can take several minutes, even for just a couple dozen documents. Once training is done, the returned model artifact contains the model’s ID number. This is important for retrieving and deploying the model later. In this how-to, I’ll skip right through to extracting data from new documents, but this (required) process of managing trained model artifacts is one of the biggest drawbacks of Microsoft Form Recognizer.
model = poller.result()
print(f"{model.status=}")
print(f"{model.model_id=}")
print(f"Number of training docs: {len(model.training_documents)}")model.status='ready'
model.model_id='8bd7251e-2dc1-49a8-944f-a0a7e3d7491e'
Number of training docs: 26Extracting form data uses a different client, the FormRecognizerClient. This time, we can send the query document from a local path.
The output document is a list of pages, each of which is a custom RecognizedForm type. This ultimately all pure Python (as far as I can tell), so it’s pretty easy to explore and learn in a REPL.
from azure.ai.formrecognizer import FormRecognizerClient
form_recognizer = FormRecognizerClient(endpoint, AzureKeyCredential(api_key))
document_path = "<<path to your local document>>"
with open(document_path, "rb") as f:
poller = form_recognizer.begin_recognize_custom_forms(
model_id=model.model_id, form=f
)
document = poller.result()
type(document[0])azure.ai.formrecognizer._models.RecognizedFormConverting the raw Form Recognizer output into a more familiar and usable Pandas DataFrame is just a matter of iterating through the pages and the discovered fields within each page.
import pandas as pd
def build_forms_dataframe(document):
"""Convert Microsoft Form Recognizer raw output into a Pandas DataFrame."""
results = []
for page in document:
for field_name, field in page.fields.items():
result = dict(
start_page=page.page_range.first_page_number,
end_page=page.page_range.last_page_number,
field_name=field_name,
confidence=field.confidence,
key_text=field.label_data.text,
value_text=field.value_data.text,
)
results.append(result)
return pd.DataFrame(results)
data = build_forms_dataframe(document)
data.head() start_page end_page field_name confidence key_text value_text
0 1 1 field-0 1.0 Changes as of: 2/6/2020 at 8:08 AM
1 1 1 field-1 1.0 Version: Current State Version 2
2 1 1 field-2 1.0 CPE: 509/545/8023
3 1 1 field-3 1.0 Flight: 2/5/20 - 2/18/20
4 1 1 field-4 1.0 Station: KLASPlease feel free to copy and use this utility function. Each row in the output DataFrame corresponds to one key-value pair extracted from the document. The field_name column contains identifiers that Form Recognizer attaches to each field it has discovered; I don’t know how it works or what it means, and honestly, it makes me wonder if I’m using the service entirely incorrectly.
Test methodology
Choosing the candidates
I first narrowed the set of potential products to those that:
- Have either a free trial or a pay-as-you-go pricing model, to avoid the enterprise sales process
- Claim to be machine learning/AI-based, vs. human-processing.
- Don’t require form fields and locations to be specified manually in advance.
- Have a self-service API.
Of the tools that met these criteria, Amazon Textract, Google Form Parser, and Microsoft Form Recognizer seemed to best fit the specifics of my test scenario.
The challenge
Suppose we want to build a service to verify and track ad campaign spending. When a customer receives an invoice from a broadcaster they upload it to our hypothetical service and we respond with a verification that the invoice is legit and matches a budgeted outlay (or not). For this challenge, we want to extract the invoice number, advertiser, start date of the invoice, and the gross amount billed.
To illustrate, the correct answers for the example invoice in the previous section are:

{
"Contract #": "26795081",
"Advertiser:": "House Majority Forward",
"Flight:": "2/5/20 - 2/18/20",
"Total $": "$33,500.00"
}To do this at scale, we need a form extraction service with some specific features:
- Key-value mapping, not just OCR for unstructured text
- Accepts PDFs
- Responds quickly, preferably synchronously.
- Handles forms with different flavors. Each broadcast network uses its own form, with a different layout and style.
We don’t need the service to handle handwritten forms, languages other than English, or images of documents. Let’s assume we don’t have a machine learning team on standby to train a custom model.
The data
The documents in my test set are TV advertisement invoices for 2020 US political campaigns. The documents were originally made available by the FCC, but I downloaded them from the Weights & Biases Project DeepForm competition. Specifically, I randomly selected 51 documents from the 1,000 listed in Project DeepForm’s 2020 manifest and downloaded the documents directly from the Project DeepForm Amazon S3 bucket fcc-updated-sample-2020.
I created my own ground-truth annotations for the 51 selected invoices because Project DeepForm’s annotations are meant for the more challenging task of template-filling.4
To evaluate Form Recognizer, I split the data randomly into 26 training documents and 25 test documents. Note that this is different from how I evaluated Amazon Textract and Google Form Parser because those services have pre-trained models for general-purpose form extraction.
Evaluation criteria
I measured correctness with recall. For each test document, I count how many of the 4 ground-truth key-value pairs each service found, ignoring any other output from the API. The final score for each service is the average recall over all test documents.
I use the Jaro-Winkler string similarity function to compare extracted and ground-truth text and decide if they match.
Form Parser attaches a confidence score to each extracted snippet. I ignore this; if the correct answer is anywhere in the response, I count it as a successful hit.
The results table (below) includes a row for custom key-value mapping. For each service, I requested unstructured text in addition to the key-value pairs, then created my own key-value pairs by associating each pair of successive text blocks. For example, if the unstructured output was
["Pay Day:", "Aug 2, 2019", "912 Silver St.", "Suite 1966"]then this heuristic approach would return:
{
"Pay Day:": "Aug 2, 2019",
"Aug 2, 2019": "912 Silver St.",
"912 Silver St.": "Suite 1966"
}Most of these pairs are nonsense, but because I evaluated with recall, this naïve method turned out to be a reasonable baseline. In fact, for Textract the results were better than the explicit key-value pair extractor.
Results
Form Recognizer performed poorly in my test. The mean recall (2.2/4) was the lowest of the three services we tested, although—interestingly—the median recall was on par with the top performer at 3 key-value pairs found out of 4.
Response times were middle-of-the-pack but not fast enough for synchronous applications.
- While less critical than the response time of a deployed model, it’s worth noting that training a model is very slow. Even with only 51 training documents, training took about 7 minutes in our experiment.
Our naïve heuristic of connecting successive blocks of unstructured text as key-value pairs yielded 2.9/4 fields recalled, better than the dedicated form extraction tool. On the other hand, 25% of our requests for unstructured text failed outright, preventing this from being a viable fallback option. No other service we tested had this problem.
- The error message suggested a problem with file or document page size, but I was unable to pinpoint the problem. The custom models processed the same documents without complaint, so we are honestly a bit confused.
Training with more documents would likely improve Form Recognizer’s performance. But with the training set size capped at 500 total pages, I’m skeptical that an unsupervised model will work well in the wild.
- As a baseline, we trained a model on all of our labeled 51 documents and evaluated it on the same training dataset. This approach only achieved 58% average recall.
| Measure | Amazon Tetxtract | Google Form Parser | Microsoft Form Recognizer |
|---|---|---|---|
| Mean recall (out of 4) | 2.4 | 2.8 | 2.2 |
| Median recall (out of 4) | 2 | 3 | 3 |
| Mean recall, custom key-value mapping (out of 4) | 2.9 | 0.4 | 2.9 |
| Mean response time (seconds) | 65.4 | 3.3 | 25.3 |
| 90th percentile response time (seconds) | 173.1 | 4.7 | 41.1 |
Final thoughts
I expected Form Recognizer would reward the overhead of training and managing custom models with superior performance, but I was disappointed. In my testing, Form Recognizer’s accuracy was poor and its response times were way too slow for synchronous use cases. I did have some success with Form Recognizer’s unstructured text output, although Amazon Textract’s unstructured output was equally accurate, did not require training and managing custom models, and did not return errors as Form Recognizer did.
If you’re committed to Microsoft Azure for other reasons and want to try Form Recognizer, I suggest skipping the unsupervised model. Invest the time to label documents with ground truth and try a supervised model. Please let us know in the comments how it goes!
References
- Listing image by Ramakant Sharda on Unsplash.
Footnotes
For invoices and receipts, in particular, see Taggun, Rossum, Google Procurement DocAI, and Microsoft Azure Form Recognizer Prebuilt Receipt model. For identity verification, try Onfido, Trulioo, or Jumio. ↩︎↩︎
The code snippets in this article work with Python 3.8, pandas 1.2.5, and azure-ai-formrecognizer 3.1.1 (which calls version 2.1 of the Form Recognizer API).↩︎
Pro tip (learned the hard way): if you’re having trouble accessing the storage container, make sure the SAS key has not expired.↩︎
Annotating form documents is very tricky, and I made many small decisions to keep the evaluation as simple and fair as possible. Sometimes a PDF document’s embedded text differs from the naked eye interpretation. I went with the visible text as much as possible. Sometimes a key and value that should be paired are far apart on the page, usually because they’re part of a table. I kept these in the dataset, although I chose fields that are not usually reported in tables. Dates are arranged in many different ways. When listed as a range, I have included the whole range string as the correct answer, but when separated I included only the start date.↩︎