Richard McElreath’s Statistical Rethinking, 2nd edition is the book I wish I’d had when I started out in data science.
My early statistical modeling approach was what McElreath calls “causal salad”: throw every remotely relevant variable into a linear regression as a potential “control” and let OLS sort it all out.1 McElreath’s mission in Statistical Rethinking is to fix this kind of thinking, by showing not only that it’s wrong but how to do it better.
Published in 2020, Statistical Rethinking is a textbook with a refreshing PopSci flavor. McElreath’s voice is familiar, reassuring, even sympathetic, and he explains concepts with allegories and examples instead of heavy math derivations. Markov Chain Monte Carlo, for example, is introduced through the character of Good King Markov, who must visit all of his island territories in proportion to their populations. His cousin, Monty uses Hamiltonian Monte Carlo to visit all of his kingdom’s villages in a mountain valley on the mainland.
With lots of code, datasets, models, and methods, Statistical Rethinking the best on-ramp to both practical Bayesian and causal modeling that I’ve seen. This is true whether the reader is completely new to statistics or an established data scientist broadening their horizons. Not surprisingly, the book has become popular among data scientists—glowing recommendations pop up regularly on Reddit, Twitter, and other forums.2
What’s the book about?
Statistical Rethinking is an introduction to statistical modeling. McElreath starts small, with the basics of probability and the philosophical essence of modeling. He introduces the foundational building blocks of single parameter estimation and linear regression, then ramps up quickly to information theory, regularization, multi-level models, sampling algorithms, generalized linear models, and Gaussian processes.
These topics are presented through the lenses of two key themes.
As you might expect from its sub-title, Statistical Rethinking is about the Bayesian approach to statistical modeling. McElreath does seem to have strong opinions about Bayesianism as a philosophy, but this is a practical book. It focuses more on the purpose, mechanics, and interpretation of models fit to real data, with McElreath’s philosophical scorn aimed primarily at the rote application of statistical conventions. Gelman, et al’s Bayesian Data Analysis remains the Bayesian bible, but I initially found much of the material in that book difficult to grok. Statistical Rethinking is an on-ramp for that book, with intuitive, step-by-step, ground-up, explanations that make few assumptions about the reader’s prior knowledge.
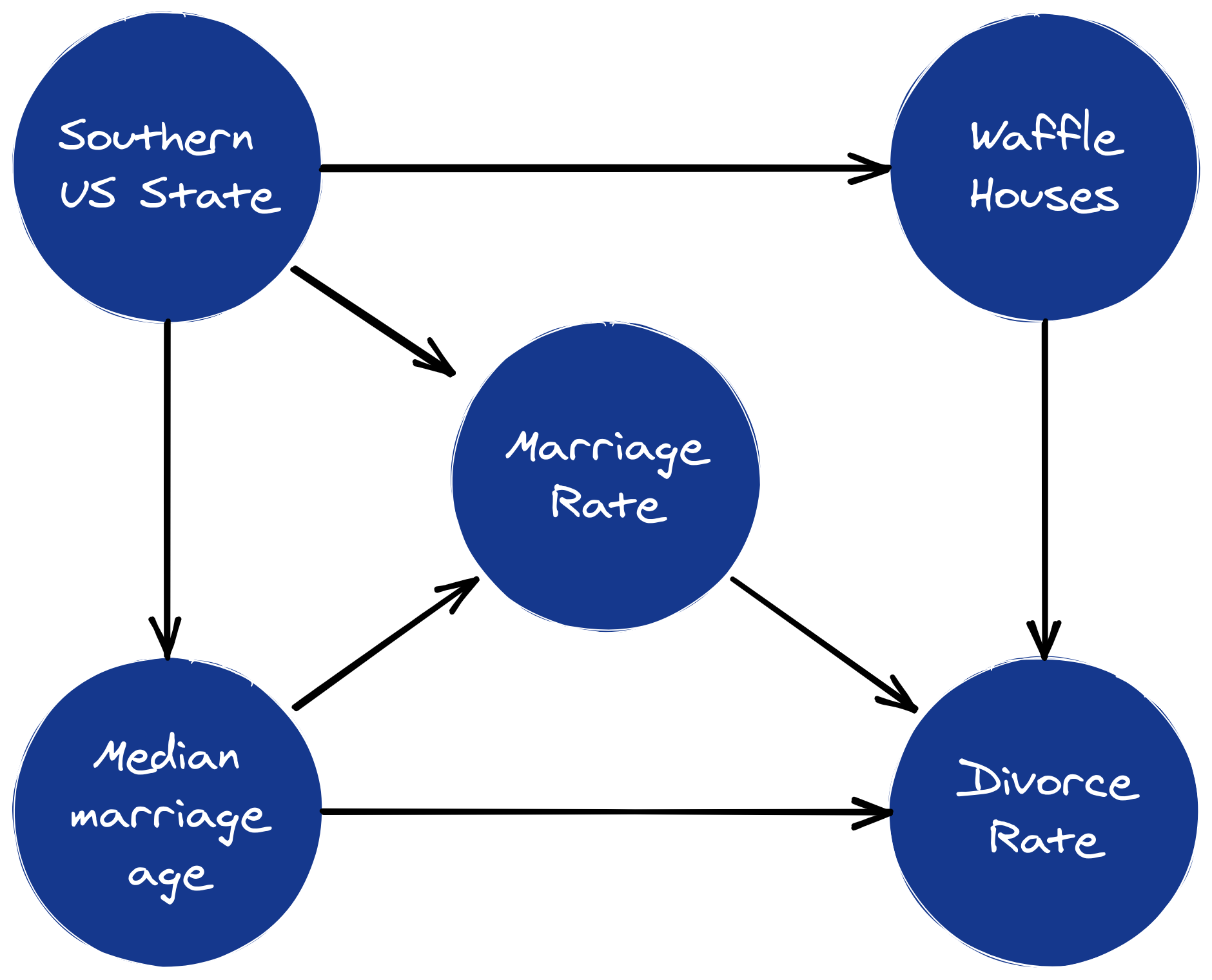
The second theme of the book is causal modeling. McElreath introduces causal Directed Acyclic Graphs (DAGs) early in the book (chapter 5 and 6) and shows how to use them to imbue models with meaning. In fact, he emphasizes that statistical models can’t have causal meaning without additional assumptions, which means we must purposefully think about causal structure as a core part of the inferential modeling process.3
McElreath’s example-based illustrations of how to use causal DAGs to inform regression models come as somewhat of a relief; I have marveled for some time at the elegance of the causal DAG framework without having a clear recipe for how to apply them to my work.
Who is the book meant for?
As McElreath says in the preface,
The principle [sic] audience is researchers in the natural and social sciences, whether new PhD students or seasoned professionals, who have had a basic course on regression but nevertheless remain uneasy about statistical modeling.
I don’t think it takes a Ph.D. to get something out of this book; even total newbies will enjoy it. The beginning of one’s data science journey might even be the ideal time to read a book like this, to inoculate against some of the “odd rituals” (McElreath’s words) of conventional statistical practice. The ground-up introduction to probability in chapter 2 is clearly meant for beginners and McElreath uses the metaphor of scaffolding for the book, in the sense that as readers gain more experience and expertise the lessons of Statistical Rethinking will be less necessary and will fall away like scaffolding. Some topics may be tough for novices; McElreath is ambitious in attempting to introduce complex concepts like splines (ch. 4) and information theory (ch. 7). He does it in the typical narrative, sympathetic, step-by-step style, though, so it works.
McElreath’s engaging style makes the book an equally great read for experienced pros. I don’t know of another author who would try to explain likelihood functions, for example, with references to Jorge Luis Borges’ The Garden of Forking Paths.

Statistical Rethinking is oriented toward researchers in scientific disciplines rather than industry data science. This primarily shows up in McElreath’s choice of examples. I don’t think it’s a problem for readers in industry; it’s not too hard to distill the lessons and translate the examples to other settings.
One thing this book is not: a reference. McElreath says it best in the preface:
This book is not a reference, but a course. It doesn’t try to support random access. Rather, it expects sequential access.
The chapter titles aren’t even descriptive—how are we to know that the chapter Ulysses’ Compass is about predictive models and the bias-variance tradeoff? Answer? We aren’t. We’re supposed to read the book in order and just enjoy the ride. The lack of formal mathematical definitions also limits the book’s use as a reference. Even if you find the right pages, it’s not a matter of a quick glance at a forgotten formula; you have to read the entire narrative of that section.
What are the concrete takeaways?
Despite its narrative feel, Statistical Rethinking is meant for the practicing data scientist, with many useful lessons for real-world work.
In my opinion, the most valuable take-home is how to use causal DAGs for real modeling work, explained and demonstrated in line-by-line detail. I’m still a little skeptical—McElreath’s examples are unrealistically simple—but at least now I know how it’s supposed to be done.
The second big take-home lesson is how to construct Bayesian models from scratch This process can be a big obstacle for the more complex but powerful methods like regression. Statistical Rethinking shows how to think about priors for a good variety of scenarios, including regression, multiple regression, proportions, and multilevel models. It also shows how to diagnose problems with priors using prior predictive simulation. This is super helpful stuff.
The specific models and methods covered in the book are highly practical; things like binomial regression, Poisson regression, multilevel models, and counterfactual posterior plots are certainly useful in industry data science, not just scientific research.
One aspect of Statistical Rethinking I especially enjoyed is the nuggets of philosophy and best practices that McElreath sprinkles throughout the book. Some of these bits of wisdom aren’t as immediately applicable as others, but they all prodded me to think more deeply about my own practice. Ultimately, that introspection is likely to have an even bigger impact than the nuts of bolts of a particular method.
Here’s an example from page 97:
Making choices tends to make novices nervous. There’s an illusion sometimes that default procedures are more objective than procedures that require user choice, such as choosing priors. If that’s true, then all “objective” means is that everyone does the same thing. It carries no guarantees of realism or accuracy.
A more practically oriented opinion, from page 225:
A very common use of cross-validation and information criteria is model selection, which means choosing the model with the lowest criterion value and then discarding the others. But you should never do this.
While Statistical Rethinking is chock-full of R code snippets, I suspect the code is less useful as a takeaway than the more abstract concepts. It is primarily based on McElreath’s own rethinking package, meaning that many of the snippets are only slightly modified calls to highly encapsulated functions for posterior approximation (quap), simulation and sampling (link, sim), and Markov Chain Monte Carlo (ulam). Under the hood, the rethinking library uses the Stan package for probabilistic programming, and I suspect most practitioners will skip the book code and work directly with Stan or one of its peers.
The Statistical Rethinking website links to many code sources, including the rethinking package and the code snippets from the book, as well as translations (by other people) to Python and Julia and re-implementations with various probabilistic programming engines. Don’t assume these projects are suitable for industry use, though, just because they’re listed on the book’s website; the code quality and licensing of these projects varies widely. The author’s own rethinking package, for example, doesn’t seem to have any license at all.
Consider working directly with one of the many probabilistic programming engines, because these tend to be thoroughly tested, documented, and maintained. Still, beware license issues—Rstan (R) and PyStan (Python) both have GPL licenses. PyMC3 (Python), NumPyro (Python), and Turing (Julia) are more permissive.
What didn’t you like about Statistical Rethinking?
No textbook is perfect, and Statistical Rethinking is no exception.
The chapter about prediction (ch. 7, Ulysses’ Compass) is not great. The key concepts are obscured by the overly cute intro allegory, then presented with unusual terminology (e.g. target to mean loss function), out of order (e.g. overfitting and underfitting before basic model evaluation), and in an offhand, almost forgotten way (e.g. out-of-sample model evaluation).
McElreath is sometimes overly iconoclastic. One example is his choice of 89% and 97% compatibility intervals (known elsewhere as credible intervals), instead of the more common 90% and 95% intervals. McElreath says the conventional levels lure readers into treating the intervals as significance tests (pp. 88, 247), but I wish he had a little more faith in the audience.
Most of the illustrative datasets in Statistical Rethinking are tiny. Multiple regression is illustrated with an example about divorce rates with one data point for each of the 50 US states (p. 124). The dataset for multilevel models has just 48 observations (p. 401) and for Poisson regression, the example has only 10 (p. 347)! These are all valid use cases, but it would be nice to see some examples with larger datasets, especially in situations where Bayesian and frequentist results differ.
McElreath occasionally omits the output of his code, as a way to induce the reader to run the code themselves. This may be great for students, but many professional data scientists don’t have the time for this.
So, should I take the time to read it?
Yes, you should read it. The practical tips in Statistical Rethinking will be immediately useful, and McElreath’s opinions will make you think more deeply about your data science craft. It’s the best introduction to practical Bayesian and causal modeling that I know of. And if that’s not convincing, read it because everybody else is.
Two suggestions, though. First, if you haven’t seen causal DAGs before, consider starting with the gentler and more thorough introduction in The Book of Why, by Judea Pearl and Dana Mackenzie, then come back to Statistical Rethinking. Second, think about working through Statistical Rethinking with a study group. Because the book is meant to be read sequentially, you’ll get the most out of it if you work straight through with persistence. In my experience, a little peer pressure makes it easier to stick to the habit. Enjoy the book, and let us know what you think!