Is it just me, or has binary classification become passé?

It seems to be getting harder to motivate data scientists to work on simple models like binary classifiers, even though they’re often the most valuable and reliable machine learning assets. As machine learning software has matured and idioms have stabilized, creating basic tabular supervised models has become somewhat rote. But rather than chasing the latest shiny ML headlines, we should take more pride in professionalizing the models we know bring value to our organizations.
I use the term professional in the sense of a job performed at a high standard of quality and completeness, and for meaningful stakes. Not all models created by a professional data scientist reach this level; most are experimental and never see the light of day—that’s normal and fine.
Model professionalization is one part of productionization.1 In addition to the items listed below—which are usually owned by a data scientist—productionization involves engineering components like data pipelines, containerization, serving at scale, and dev ops.
Hang on a sec, you say, didn’t you write recently that modeling should be the last priority, behind problem formulation and data?
I did indeed, and I continue to believe that. But sometimes the pendulum can swing too far the other way. For all the breathless headlines about text generation and scene segmentation, the workhorse of industry data science and machine learning remains predictive binary classification with tabular data. The examples are endless; here are a few, just to make sure we’re on the same page:
- How likely is a customer to renew their subscription to our service?
- What’s the probability a user will click on an ad, song, movie, or search result?
- Is a financial transaction fraudulent or not?
Given a dataset, creating tabular supervised models is effectively boilerplate at this point.2 Choose your favorite ML framework—scikit-learn, lightGBM, XGBoost, etc—split the data into train, validation, and test sets, choose the random forest or gradient boosted trees hyperparameters that maximize a standard metric, wrap it all in a pipeline, and ship it.
That’s the classroom version, anyway. For a model that’s going to be deployed, it’s just the start. Here are some other things you should think about as part of the modeling process.
The professional model checklist
Model usage
Ethics and fairness. I can’t do this topic justice in two sentences. At a minimum, be sure that vulnerable or protected classes of users are treated fairly by the model. For more, follow the work of the Algorithmic Justice League and the Center for Applied Data Ethics.
Causal interpretation. Presumably, some action will be taken based on the model’s output. What is that likely to be? Does the model plausibly identify the causal impact of that intervention?
Calibration. If the model output will be interpreted as a probability, it needs to be calibrated. This is also a good way to make the overall system more robust to model iterations. See the scikit-learn user guide and this blog post for more.
Thresholding predictions. If model consumers need binary predictions, how should we threshold numeric model output? The business evaluation criteria (next section) may play a large role in this decision.
Evaluation and monitoring
Business evaluation criteria. How will business stakeholders evaluate the model system? How do the model evaluation metrics (next item) relate to the business criteria? What’s the revenue impact, for example, as a model’s precision increases?
Model evaluation criteria. We evaluate predictive model performance on validation and test sets, but how should we construct those sets and which metric should we use? Many papers and textbooks assume the validation and test sets can be randomly sampled from the data, but in real applications, there is usually some un-modeled time component that makes temporal splits a better choice. For binary classification, we have many metrics to choose from: precision, recall, F2 score, AUC, and more. Which one best drives the business objectives?
Re-training cadence. Things change. Products and business partnerships evolve, data definitions are tweaked, evaluation criteria are updated, even the relationship between the features and the target variable changes over time. How often do we need to re-train our model to keep it accurate? Who will be responsible for keeping that schedule?
Monitoring. What information do we need to monitor once the model is in production? How will we decide if the model needs to be debugged or re-trained?
Data
Feature engineering. This is sometimes included in the model building process, but increasingly features are defined and computed in a separate feature store.
Target variable balance. Take fraud prevention for example, where incidents of confirmed fraud are a tiny fraction of the data. Do the positive cases need to be up-weighted to get the model to do something useful? If so, how?
Feature balance. This is important if the model system will be evaluated in a stratified way. Suppose we have a model that determines bus schedules in different US cities. We may decide to train with data from multiple cities, but each city’s transit agency evaluates the results separately.3 Cities with smaller transit systems will see worse model performance and worse service, and their transit agencies will complain.
Re-training data. Let’s look at a toy scenario of a loan default model using just two features: the size of the loan and the applicant’s historical late payment rate. In our original dataset, we have a mix of defaults (orange triangles) and loans paid in full (blue circles), and it’s easy to train a binary classifier.

Hypothetical loan data, with the decision boundary of a binary classifier. For some time, we make loan approval decisions with this classifier. After a while, though, the economy has changed; inflation and unemployment are up, but the government sent two rounds of stimulus checks, which many people used to pay off old credit card debt. All these changes mean we need to re-train the model, but now we only have data on one side of the model’s decision boundary. As a result, the next version of the model may not be so great.
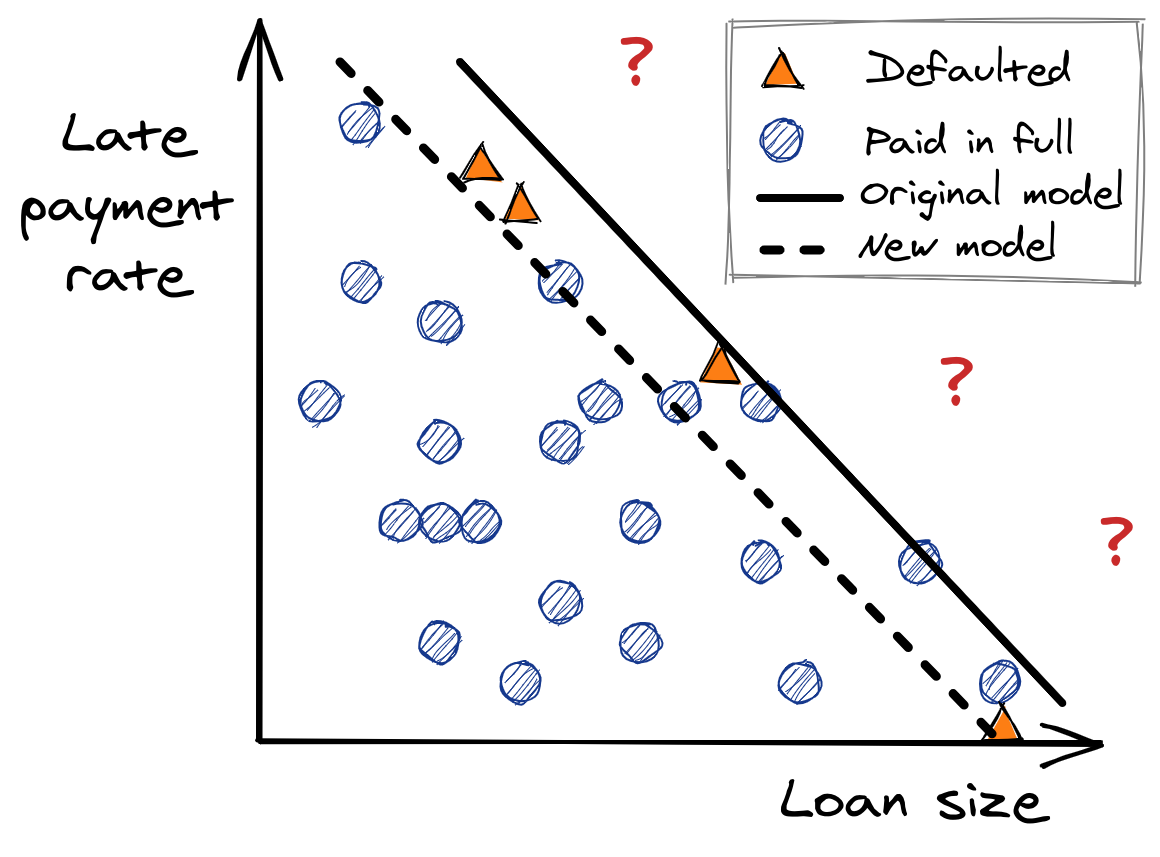
More hypothetical loan data. The policy based on our initial model (solid line) prevents us from observing data in a large part of the feature space, which causes our new model (dashed line) to suffer. Feedback loops. A more extreme version problem occurs when the model is the thing that causes the underlying data generating process to change. Recommender systems are especially notorious for this, creating echo chamber behavior where repeated exposure to a topic reinforces users’ opinions about that topic.
Interpretation and explanation
Explain how the model works to stakeholders. Partners in business units are on the hook to deliver results and may be hesitant to cede control to a model-based system they don’t understand (especially with so much AI hype floating around). How to explain to business units so they trust it and buy in? Christoph Molnar’s book Interpretable Machine Learning is a fantastic resource for this.
Explain surprising predictions. Models frequently make predictions that don’t match our intuition. Well-trained models are sometimes correct in these situations, but it’s still unsettling for business stakeholders and end-users. When somebody complains about a specific prediction, we need to be ready with tools to explain where that prediction came from. Interpretable Machine Learning covers this use case as well.
Model uncertainty and debugging. Models are also sometimes wrong with surprising predictions, for fixable reasons. The tools we use to explain predictions should also help us to find and diagnose real problems, like insufficient data or unusually large variation in the target variable in some part of the feature space.
What else?
This checklist is based on my own experience and I’m sure I’ve missed important items. Please leave a comment below with your thoughts.
Footnotes
I don’t like writing huge words like professionalization and productionization any more than you like reading them. Unfortunately, they capture the relevant concepts with more precision than any alternatives I can think of. Productionization in particular, contrasts with productization. The former is about getting a prototype ready for a production system, while the latter is about creating a commercial product.↩︎
The phrase “given a dataset” does a lot of heavy lifting here; building a good dataset is more valuable than any model. I’m ignoring it a little here because it’s often done separately from the modeling process.↩︎
We might train a cross-city model for statistical reasons, run-time speed, or lower maintenance overhead. See this article for a discussion of the tradeoffs.↩︎